

错误描述:
反序列化时出现“base-64 字符数组的无效长度”错误提示的解决程序中实现了这样一个功能,将一个对象序列化后,作为参数传递给另一个页面,这个页面得到参数并反序列化后还原此对象,但是在运行时有时正常,有时出现“base-64 字符数组的无效长度”的错误提示。
解决方案:
1、根据现象的解决方案
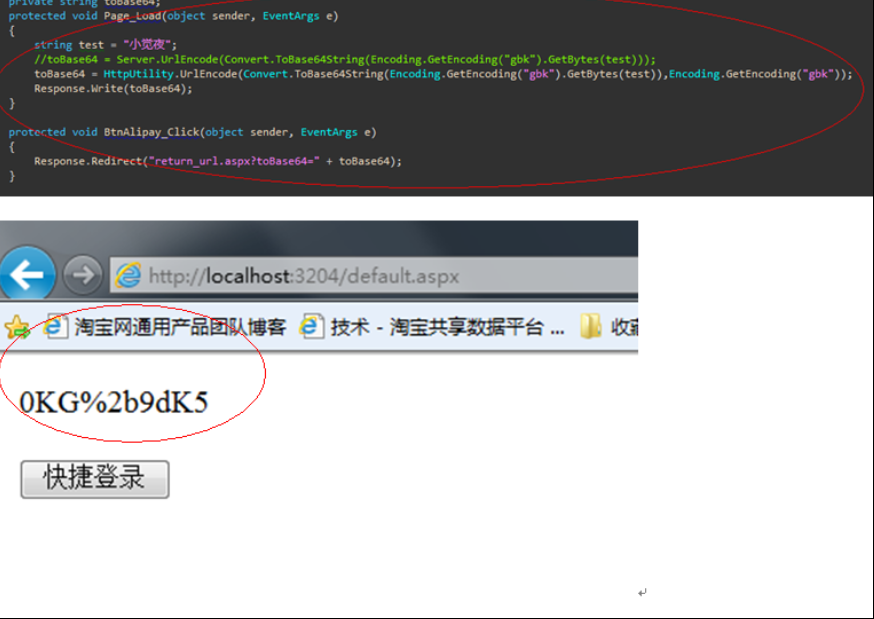
在网上查找资料,都是说在使用Convert.ToBase64String()方法对字符串进行Base64编码时,需要使参数的长度等于4或4的偶数倍数,否则将抛出“FormatException”异常(这个观点并不是正确的)。但是我这里使用的参数是使用Convert.ToBase64String()方法生成的,理论上是没有问题的。于是对比用Convert.ToBase64String()生成的字符串A与反序列化前Convert.ToBase64String()所使用的参数字符串B,发现A与B之间有差异,A中的加号变成了空格(base64编码后是允许存在’’)。这是由于网页传递参数时,会将加号编码成空格,但是在解码时却不会解码空格,结果就造成了字符串B不正确,无法背编码。确认了问题就好办了,在得到序列化字符串后,使用String.Replace("", "")先将空格编码,然后再作为参数传给另一页面传递,这样页面在提取参数时才会将“”解码为加号,参数没有差别,在执行反序列化成功就通过了。
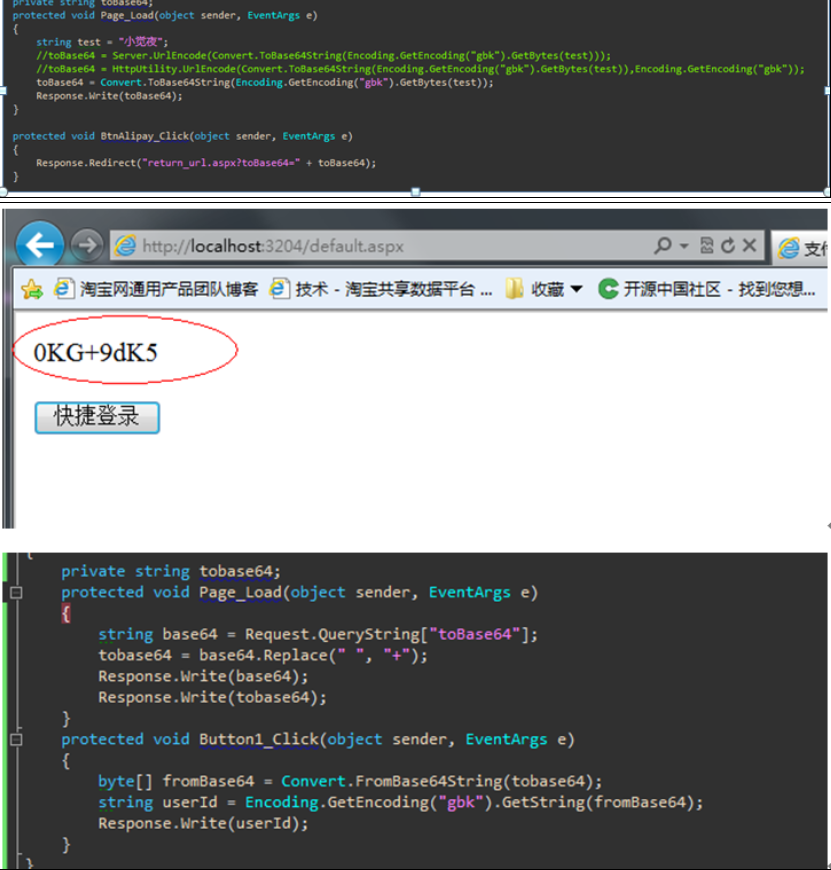
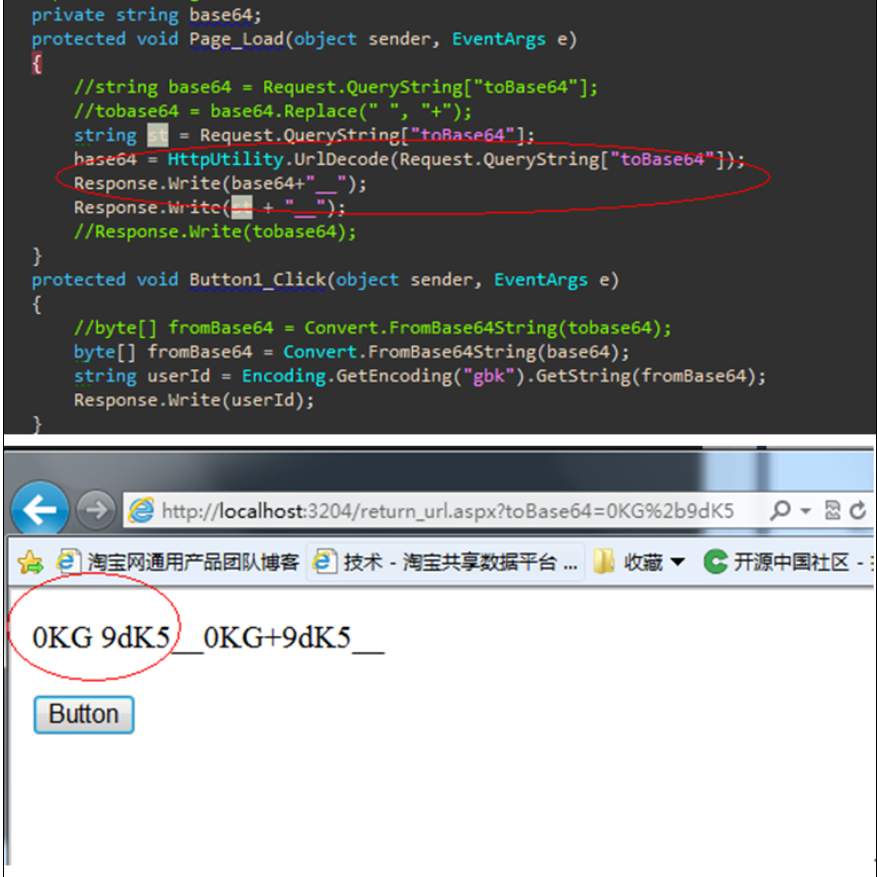
http://localhost:3204/return_url.aspx?toBase64=0KG+9dK5![]()
不过通过Request.QueryString["toBase64"]获得到的值是:

2、根据本质的解决方案:
后面再去网上搜索了资料,我们对对象Base64编码后的字符串应先行url编码再传递,这样在url传递的参数就不存在’+’了。而在获取参数端是不需要再解码,
因为使用默认的Request.QueryString和Request.Form时已经自动执行了一次解码,使用的解码格式是服务器端设置的默认编码格式。
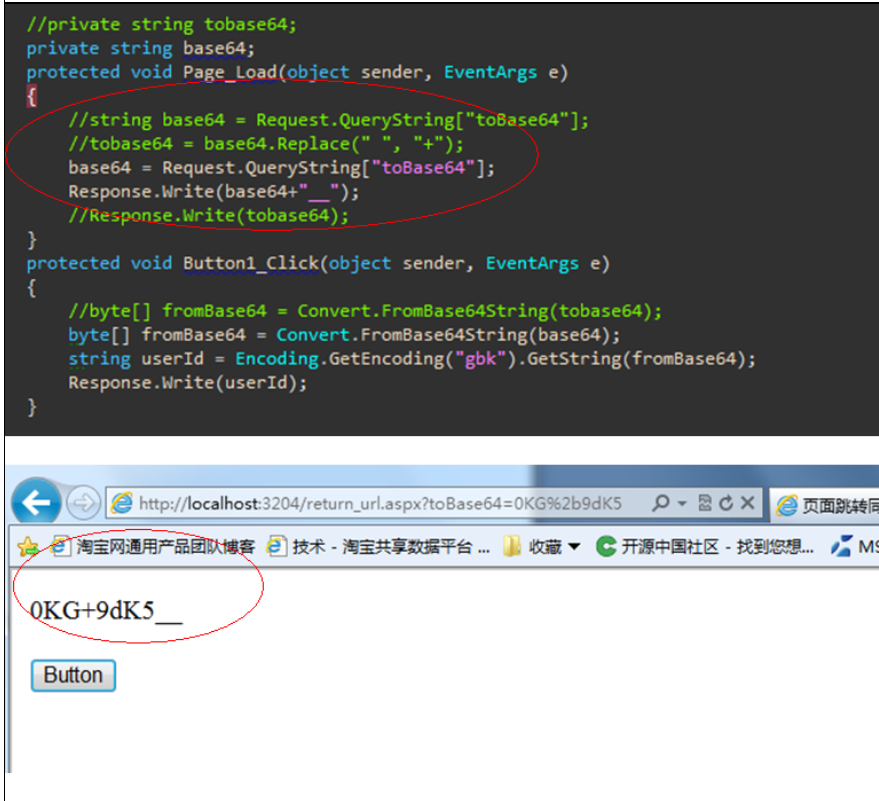
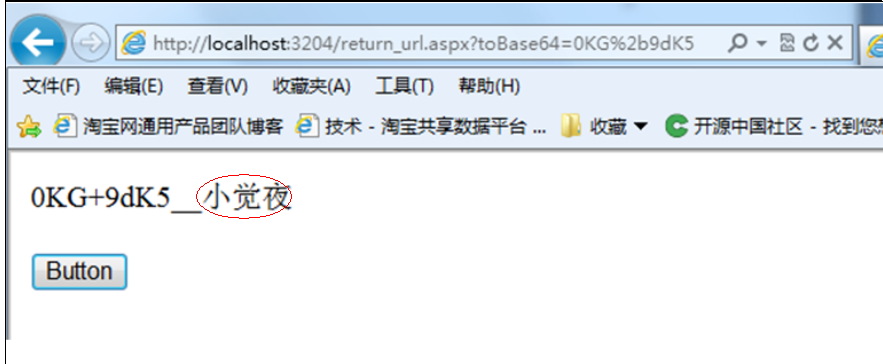
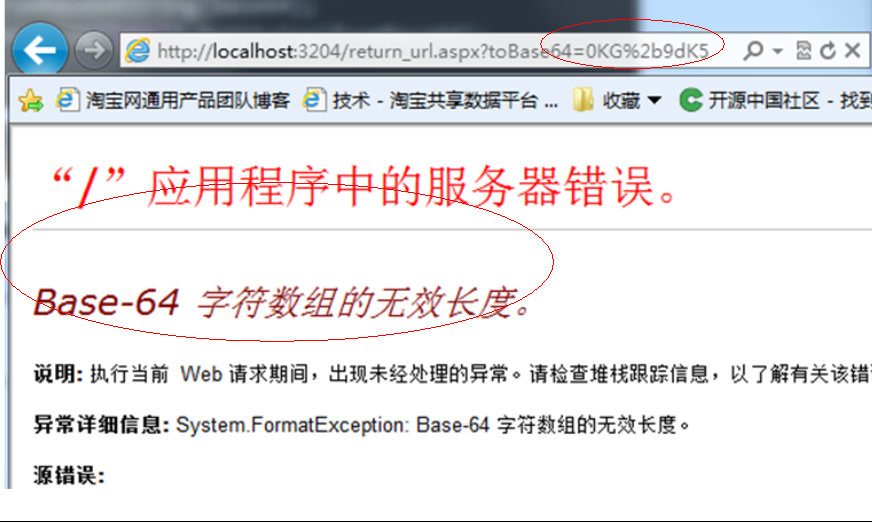
而如果对Request.QueryString得到的值进行UrlDecode解码再进行ToBase64就会出错,因为就相当于2次解码。
分享资料
参数编码规范
一.摘要
我们经常要在页面传递中文数据,但是往往被文字编码所困惑.有时不了解到底是浏览器编码问题还是服务器编码问题.本文分析了互联网传递数据的编码原理, 并且提出了完善易用的解决方案.
二.原则
避免在get或者post参数时直接传递中文字符.中文参数需要经过编码后再传递.服务器端要使用相同的编码格式进行解码
三.错误观点
1.很多程序员认为url中可以传递中文. url中并不能携带中文参数.如果我们在浏览器中输入"http://localhost/?a=中文",感觉上我们在url中带了中文,实际上当按下回车键后,浏览器自动将其中的"中文"汉字进行编码后传递给服务器.
2.当获取中文参数产生了乱码时, 往往首先检查服务器端程序的编码格式. 很多人认为url可以传递中文,不知道浏览器有自动编码的行为, 所以单纯的认为问题出在服务器端.其实即使在服务器端找到了正确的编码格式,我们也不应该轻易地改变服务器的默认编码格式.
3.传递参数前编码,使用Request对象获取参数时解码 很多的程序员认为认为,传递参数时我们使用UrlEncode等方式编码, 在接收时应该使用UrlDecode解码.这是常见的错误请大家一定要注意,使用默认的Request.QueryString和Request.Form时已经自动执行了一次解码,使用的解码格式是服务器端设置的默认编码格式.
四.原因
传递中文字符时,自动的编码解码格式和浏览器与服务器的设置有关. 测试Firefox3和IE6的Get方式发送中文参数, Firefox默认使用UTF-8格式编码中文参数, 而IE6即使在高级设置中设置了"总是以 UTF-8 发送URL", 仍然自动使用GB2312编码中文参数. 对于服务器端我们可以自由的控制解码的格式.但是往往是通过更改服务器配置进行全局的统一设置.比如对于ASP.NET程序.可以在Web.Config中设置服务器段的编码和解码格式: <globalization culture="zh-CN" uiCulture="zh-CN" requestEncoding="UTF-8" responseEncoding="gb2312" /> 但是我们没法控制浏览器端行为.用户可能使用不同的浏览器.
五.解决方案
1.统一默认的编码格式 (1)设置服务器端的编码格式为UTF-8 (2)传递参数全部进行编码,.服务器端(C#)使用Server.UrlEncode方法,客户端(javascript)使用encodeURIComponent方法. 说明: 客户端的javascript函数encodeURIComponent只能使用UTF-8编码格式. 所以需要设置服务器端request和response都为UTF-8. 缺陷是如果某些合作伙伴必须传递其他的编码格式的参数, 则服务器端或获取到乱码.此方案实现简单,适合大部分场景. 2.通过编码参数指定编码格式 为了解决可能存在的无法统一编码格式的问题, 我们使用一个参数"encoding"来显示的指定编码格式.encoding参数需要在所有的请求中传递,无论是get还是post. (1)对于javascript客户端编码而言, 仍然使用encodeURIComponent方法编码, 此时指定encoding参数的值为"UTF-8". (2) 对于传入给服务器端的其他编码格式, 比如GB2312, 我们不能使用默认的Request.Form或者QueryString方法进行编码.因为服务器端的编码格式可能设置为了UTF-8.此时使用 Request.Form或者QueryString会自动使用服务器端指定的编码格式进行解码. 所以需要使用下面的方法自己处理请求,获取参数:
1 /// <summary>
2 /// 根据指定的编码格式返回请求的参数集合
3 /// </summary>
4 /// <param name="request">当前请求的request对</param>
5 /// <param name="encode">编码格式字符串</param>
6 /// <returns>键为参数名,值为参数值的NameValue集合</returns>
7 public static NameValueCollection GetRequestParameters(HttpRequest request, string encode)
8 {
9 NameValueCollection result = null;
10 Encoding destEncode = null;//获取指定编码格式的Encoding对象
11 if (!String.IsNullOrEmpty(encode))
12 {
13 try
14 {
15 //获取指定的编码格式
16 destEncode = Encoding.GetEncoding(encode); }
17 catch
18 {
19 //如果获取指定编码格式失败,则设置为null
20 destEncode = null; }
21 }
22 //根据不同的HttpMethod方式,获取请求的参数.如果没有Encoding对象则使用服务器端默认的编码.
23 if (request.HttpMethod == "POST")
24 {
25 if (null != destEncode)
26 {
27 Stream resStream = request.InputStream;
28 byte[] filecontent = new byte[resStream.Length]; resStream.Read(filecontent, 0, filecontent.Length);
29 string postquery = destEncode.GetString(filecontent);
30 result = HttpUtility.ParseQueryString(postquery, destEncode); }
31 else
32 { result = request.Form; }
33 }
34 else
35 {
36 if (null != destEncode)
37 { result = System.Web.HttpUtility.ParseQueryString(request.Url.Query, destEncode); }
38 else
39 { result = request.QueryString; }
40 }
41 //返回结果
42 return result;
43 }
另外本方法如果没有传递Encoding或者传递的字符串无法转换成强类型的Encoding对象, 则使用服务器端默认编码格式(即直接使用Request对象的QueryString和Form获取参数). 六.Javascript编码方法 发送请求的一方叫做客户端.我们经常需要使用Javascript在客户端编码中文参数.下面javascript中和编码有关的函数: 函数名称 函数说明 解释 escape() escape() 函数可对字符串进行编码,这样就可以在所有的计算机上读取该字符串。 该方法不会对 ASCII 字母和数字进行编码,也不会对下面这些 ASCII 标点符号进行编码: - _ . ! ~ * ' ( ) 。其他所有的字符都会被转义序列替换。


escape和unescape 在V3版本的标准中已经不在推荐使用.应该用encodeURI和encodeURIComponent方法.对于一个URI, 如果我们希望将它作为完整的网址发送请求, 但是上面带有中文, 则应该使用encodeURI方法.如果是要编码参数,则应该使用encodeURIComponent. 下面举例说明这两个方法的区别: document.write(encodeURIComponent("http://www.w3school.com.cn")+ "<br />") document.write(encodeURI("http://www.w3school.com.cn")+ "<br />") 结果 http%3A%2F%2Fwww.w3school.com.cn http://www.w3school.com.cn![]()
七.浏览器自动编码 Get请求 对于Get方式发送的请求, 不同的浏览器使用不同的编码方式自动为中文参数编码. 比如:Firefox/3.0.5 使用UTF-8, IE6使用GB2312. Post请求 对于Post方式发送的请求, 表单中的参数值对是通过request body发送给服务器,此时浏览器会根据网页的ContentType("text/html; charset=GBK")中指定的编码进行对表单中的数据进行编码,然后发给服务器。在HTML代码的Head中添加: <meta http-equiv="Content-Type" content="text/html;charset=gb2312" /> Firefox/3.0.5 会使用根据charset中设置的编码格式编码post的中文参数. IE6不起作用. 实验表明使用客户端浏览器默认编码格式具有不确定性.所以传递中文时我们要手工编码参数.
总结:
碰到问题应该是去追究本质原因,而不是找到现象就好了,比如第一个方法,就是说我只是将问题解决了,不过根本不知道+号为什么会变成空格的。第二个方案是了解本质原因,根据本质原因处理问题。