

聊聊数据库中的烂索引
背景
索引是数据库中用于加速查询的常用组件,它通过对数据冗余和重组织来加速 SQL 查询。通常来说,恰当的索引可以提升系统的查询性能。 关于索引存在一些误解,如:索引总是能提升查询性能,因此索引越多越好,比如下图中的例子

只看收益,不看代价是不行的。分布式数据库系统一般支持两类索引:由分布式全局事务维护的全局索引、由本地事务维护的本地索引。这两类索引都会不同程度影响系统的写入性能,下图展示了建立不同数量的索引时,对系统的写入性能的影响。
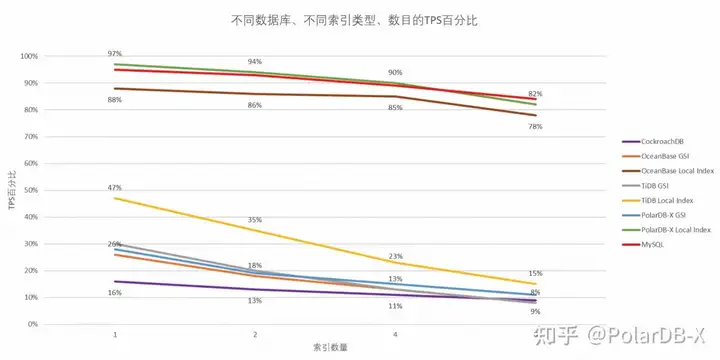
可以看出创建 1 个全局索引,就会使系统的写入性能降低至原来的约 30%;单看 MySQL,在创建 8 个索引(本地索引)的情况下,写入性能会降低至原来的 85%(引用自我们的历史文章 TiDB、OceanBase、PolarDB-X、CockroachDB 二级索引写入性能测评,感兴趣的读者可深入阅读)。 因此,在我们享受索引带来的查询加速收益时,还需关注其引入的维护开销。特别是当引入一个索引没能带来预期收益、或者带来的开销远大于其带来的查询加速收益时,索引反而成为一种负担。我们称这类索引为烂索引,避开它们可以帮助数据库获得更好的写入性能。 回顾文章开头举例的表 warehouse,你能看出其中有几个烂索引吗?我们先讨论一下应用中常见的烂索引,然后在文末公布答案。
低频访问索引和许久未访问索引
新建的索引并未按照预期目的被数据库优化器使用时,就是一个烂索引,它隐藏在数据库中,消耗着写入性能,却并未带来查询性能增益,及时发现这类索引并进行清理是十分必要的。此外,还有一些索引在一段时间内被高频使用,但随着业务的变动,这些索引不再被使用,但却一直被遗留下来,这也是烂索引。 对于上述情况,PolarDB-X 提供了 INFORMATION_SCHEMA.GLOBAL_INDEXES 视图,用于查询表中全局索引被使用的情况,有了它,哪些全局索引在 “磨洋工”,哪些全局索引 “出工又出力”,一目了然。

低选择性索引
索引的选择性是指不重复的索引值的个数(也常被称为基数)和数据表的记录总数 (#T) 的比值,可由定义知道它的取值范围在 1/#T 到 1 之间。索引的选择性越高则查询效率越高,因为选择性高的索引可以帮助数据库在查找时过滤掉更多无效的行。一个正面例子是主键索引,由于主键是不重复的,因此其选择性为最大值 1,数据库利用主键查找数据时效率很高。一个反面的例子是,在性别、isDelete 等属性上建索引。 如何发现这些低选择性的索引呢?最直接的办法是人工检查每个索引的真实含义,排除掉 “性别”“Delete 标志” 之类含义的索引。此外对于全局索引,PolarDB-X 支持用 INFORMATION_SCHEMA.GLOBAL_INDEXES 视图查看全局索引的基数和记录总数,我们可以根据这两个指标算出索引的选择性。

重复索引
重复索引是指在相同的列上按照相同的顺序创建了同类型的索引,Polardb-X 不会禁止用户创建多个重复的索引。由于数据库在写入数据时,需要同步维护索引,因此多个重复的索引就需要数据库分别维护,此外优化器在优化查询语句时,也需要对这些重复索引逐个考虑,这会影响性能。 刻意引入重复索引的场景不常见,但不小心引入却是可能的。如下面的 SQL 是 PolarDB-X 中的单表,
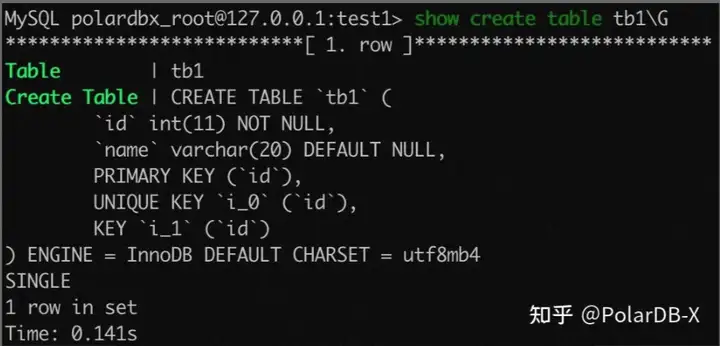
用户可能想创建一个主键,然后为其加上 unique 限制,然后再加上索引以供其查询使用,实际上上述写法会创建出 3 个相互重复的索引,其实并不需要这么做。 一些索引从定义上来看是非重复索引,但从效果上来看,又是重复的。比如下面的建表语句,

一些用户可能会将查询 SQL 的 where 条件用到的列都建成索引,因此创建了索引 idx_id_name 。但是通常数据库在构建索引的时候,都会在索引的 value 属性中填入主键,以方便回表。因此索引 idx_name 的数据中是包含了主键 id 的,idx_name 和 idx_name_id 效果相同。请避免构建这样的索引。
冗余索引
冗余索引和重复索引有所不同,如果创建了索引 (A, B),再创建索引 (A),后者就成了冗余索引。因为 (A) 是 (A, B) 的前缀索引,优化器使用索引时存在 “最左匹配原则”,即会优先使用索引中的左侧列进行匹配,索引 (A, B) 是可以当做索引 (A) 来使用的。 冗余索引经常发生在为数据表添加新索引的时候,一些用户更倾向于添加新索引,而不是在现有索引上进行扩展。我们应当优先考虑在已有的索引上做扩展,而非随意添加新索引。如果确需添加新索引,也应当格外注意新引入的索引是否是一个冗余索引,又或者新索引是否会让旧有的索引变成冗余索引。当然,一味地扩展现有索引也不可取,可能会导致索引长度过长,从而影响其他使用该索引的 SQL,这是一个 trade off。 除了考虑 “最左匹配原则”,我们还需注意 unique 约束。在有 unique 约束的情况下,一些看起来冗余的索引,实际上却并不冗余。

这里索引 idx_id_name 是无法完全替代索引 idx_id 的,因为索引 idx_id 除了方便按照 id 进行查找的作用外,还可以约束 id 不重复,而索引 idx_id_name 只能保证 (id, name) 不重复。
全局索引分区规则重复
像 PolarDB-X 这样的 Shared-Nothing 架构的分布式数据库一般会引入 “分区” 的概念,用户在建表时指定一个或若干个列为分区键,数据会在数据库内部按照分区键进行路由,从而将数据存储至不同的 DN 节点。如果一个查询语句的 where 条件中包含分区键,优化器就可以快速定位到一个具体分区并进行数据查找,但如果查询语句的 where 条件不含分区键,该查询就需要扫描全部分区,这有些类似于单机 mysql 的全表扫描,全分区扫描对于分布式数据库来说开销很大。 在实际数据库投入生产使用时,一个维度的分区往往不够灵活,将查询语句的 where 条件限制在必须包含 “分区列” 不够自由。分布式数据库一般会支持全局索引,它冗余了主表上的部分数据,并采用与主表不同的分区键,查询时首先根据全局索引的分区键定位到一个分区,然后从分区中查到主表的分区键和主键,最后回表得到完整数据。 全局索引让用户的查询语句不再受到 “where 条件必须包含主表分区列” 的限制,且能避免全分区扫描的代价。从上文可知,用好全局索引的前提是设计良好的全局索引的分区方式,尤其是要避免全局索引和主表的分区方式重复,比如下面的表结构中,全局索引 g_id 和主表 tb4 的分区方式完全一致,g_id 让系统付出了写入代价,却没有带来查询性能的增益。

全局索引分区大小不均匀
全局索引需要指定分区键,它的数据是按照分区规则存放于 PolarDB-X 的不同 DN 节点中的。设想,如果全局索引的分区规则设计的不够好,就会导致分区不均,一些 DN 节点存储大量数据,且承受大量的读写负载,而另一部分 DN 节点处于空闲状态。这造成了资源浪费,且会使数据库系统过早地到达性能瓶颈。 如下图,假设有一个业务系统建立了 seller_order 卖家订单信息表,该业务系统的特点是绝大部分订单来自于少数几个大卖家。我们只关注 seller_order 表上的全局索引 g_seller_id,它使用卖家的 seller_id 做分区键。我们假设有个大卖家的订单量占全部系统的一半,其在全局索引 g_seller_id 上的数据被路由到 P5 分区。可以看到 P5 分区会承受其它分区数倍的负载。
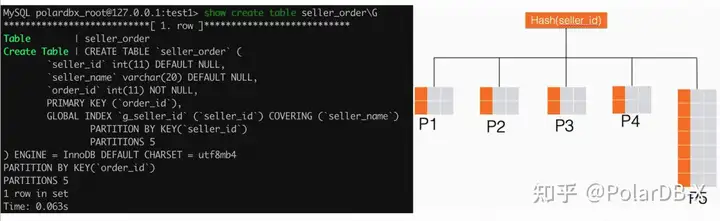
良好的全局索引应当保证数据尽可能均匀分布在不同分区。
全局索引中的 range 分区
在 PolarDB-X 中使用 range 分区作为全局索引的分区策略时应该额外注意,尽量避免将时间列作为分区列。
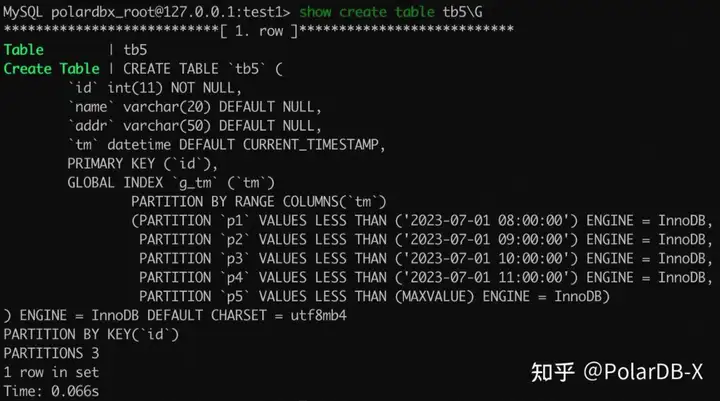
如上建表语句所示,全局索引 g_tm 使用了 tm 作为 range 分区的分区列,其默认值为当前时间。这里我们只考虑全局索引 g_tm,其分区 p5 是一个 catch-all 分区,在 '2023-07-01 11:00:00' 时间点以后,所有待插入的新数据都会被路由到 p5 分区(这是由新数据的 tm 列的值以及全局索引 g_tm 的路由规则决定的),因此 p5 分区会成为数据写入的瓶颈,p5 分区所在 DN 上的数据量也将一直累积。 未来 PolarDB-X 将针对这一场景做出优化,但目前我们不推荐本例中的用法。
总结
我们先来回答一下文章开头提出的问题。warehouse 表中有 4 个烂索引,分别是:重复索引 idx_id(与主键重复)、重复索引 idx_id_order_name(和主键效果一致)、冗余索引 idx_order_id_order_name(索引 idx_order_id_order_name_item_id 可以代替它)、低选择性索引 idx_deleted_order_id。 本文总结了一些常见的烂索引及其低效的原因,定期检查和清理这些烂索引,可以有效提升数据库的写入性能。可能有读者会问,表太多、索引太多,没精力挨个检查怎么办? 没关系,PolarDB-X 最新推出 inspect index 功能,支持一键自动诊断烂索引,还能给出原因和整改建议,本文提到的烂索引都能识别。
作者:未启
本站大部分文章、数据、图片均来自互联网,一切版权均归源网站或源作者所有。
如果侵犯了您的权益请来信告知我们删除。邮箱:1451803763@qq.com