

Python 爬取免费小说思路
Python 爬取免费小说思路
代码解析
爬取东西基本的四行代码:
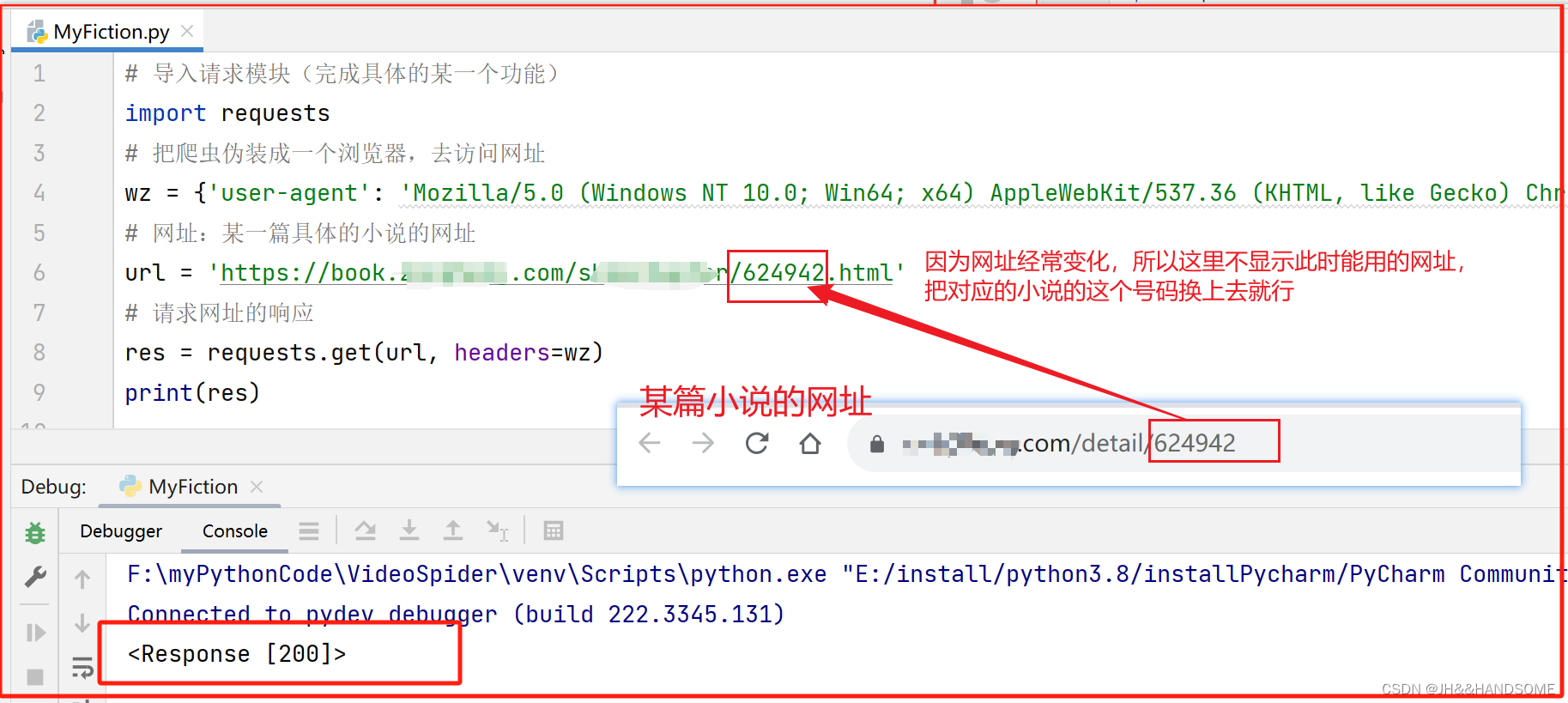
user-agent
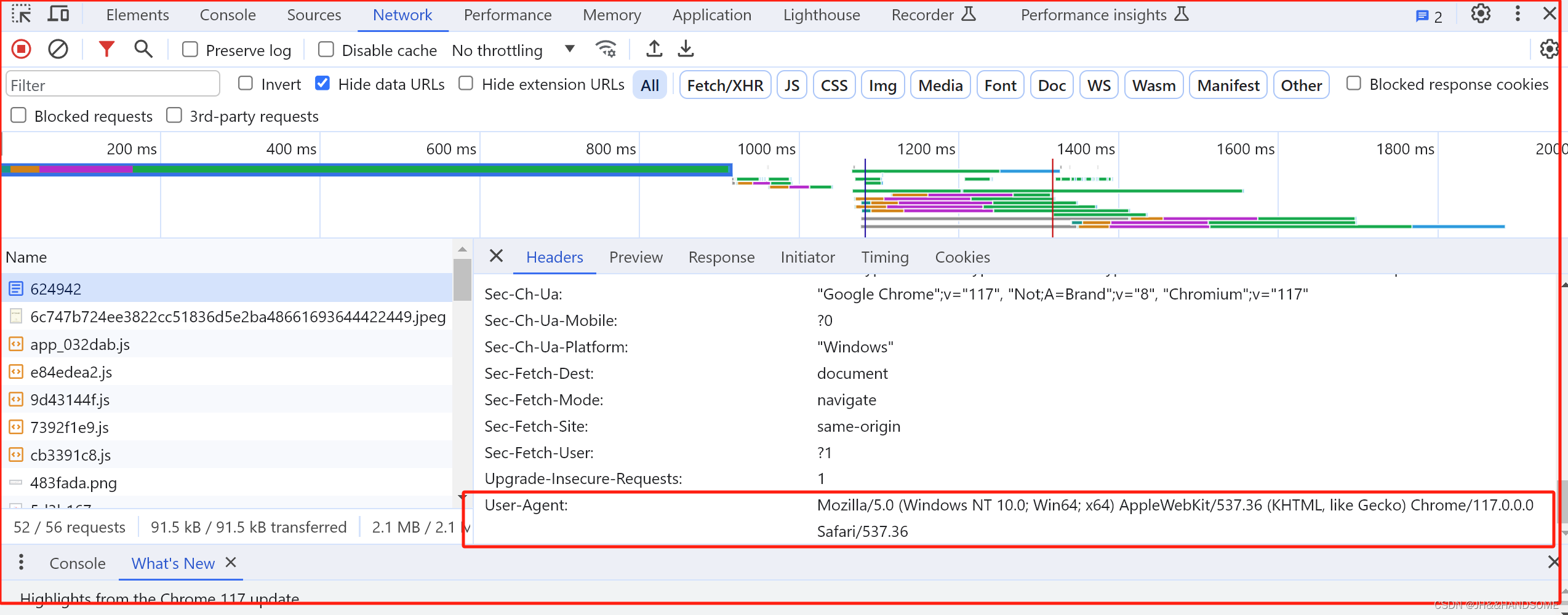
安装模块
cmd 打开小黑窗,执行安装模块命令
模块的作用:完成具体的某一个功能
pip install bs4 -i https://mirrors.aliyun.com/pypi/simple/ pip install lxml -i https://mirrors.aliyun.com/pypi/simple/
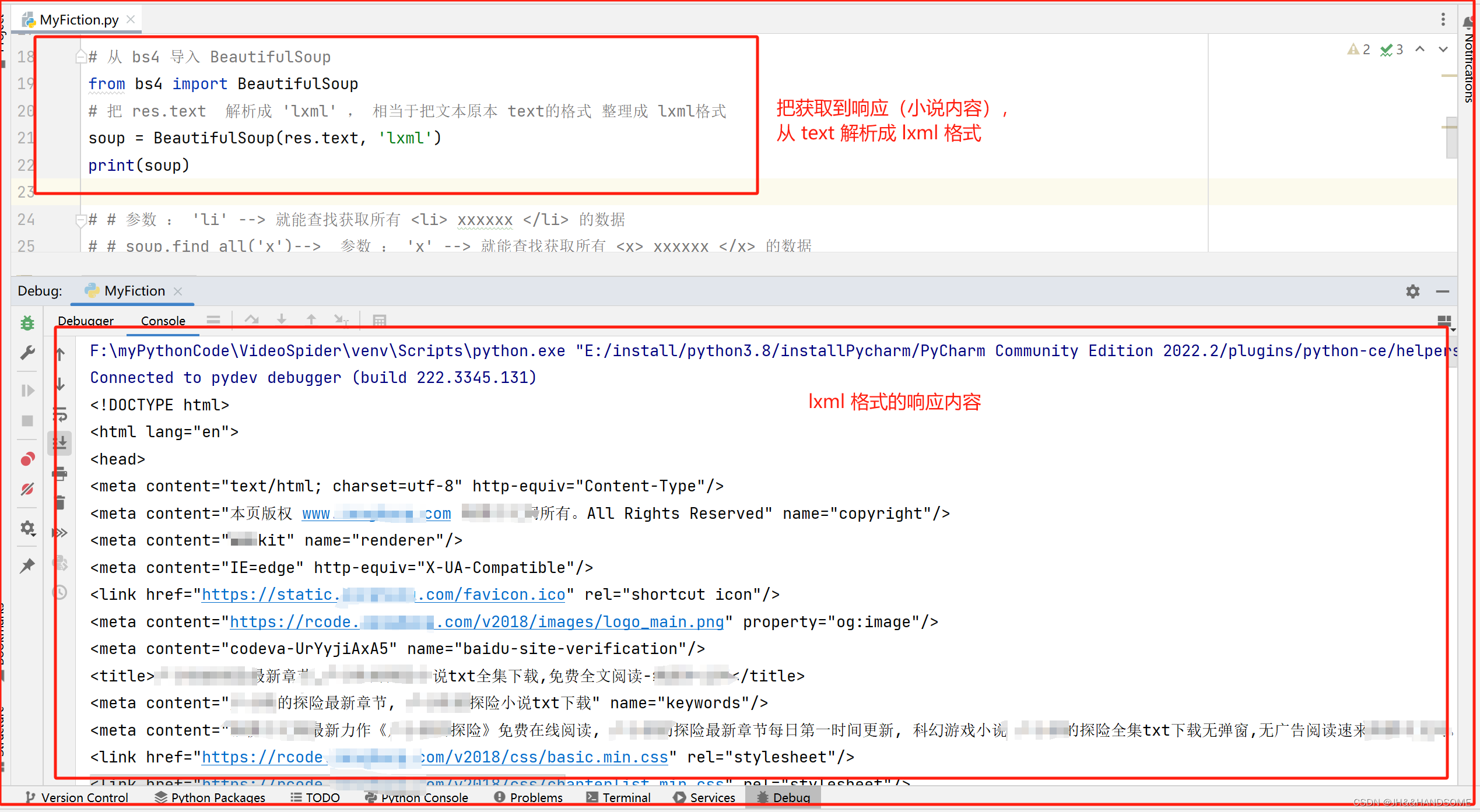
从 bs4 导入 BeautifulSoup ,
把 res.text 解析成 ‘lxml’ , 相当于把文本原本 text的格式 整理成 lxml格式
查询某个标签开头的数据
解释这行代码的作用:
soup.find_all('x')--> 参数: 'x' --> 就能查找获取所有 <x> xxxxxx </x> 的数据
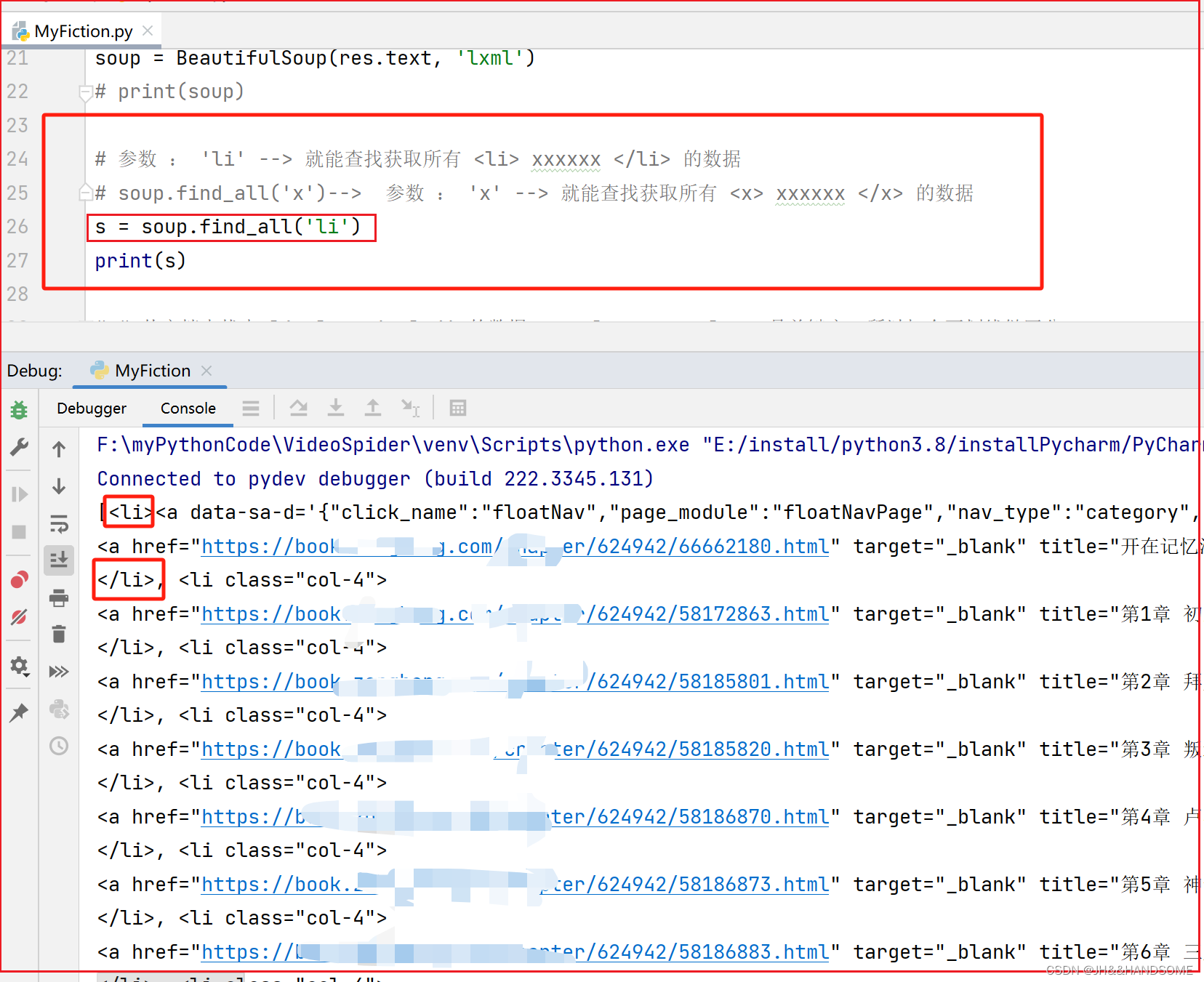
筛选
筛选小说:思路是从大到小筛选,实际先筛选小的,找不到再扩大范围筛选
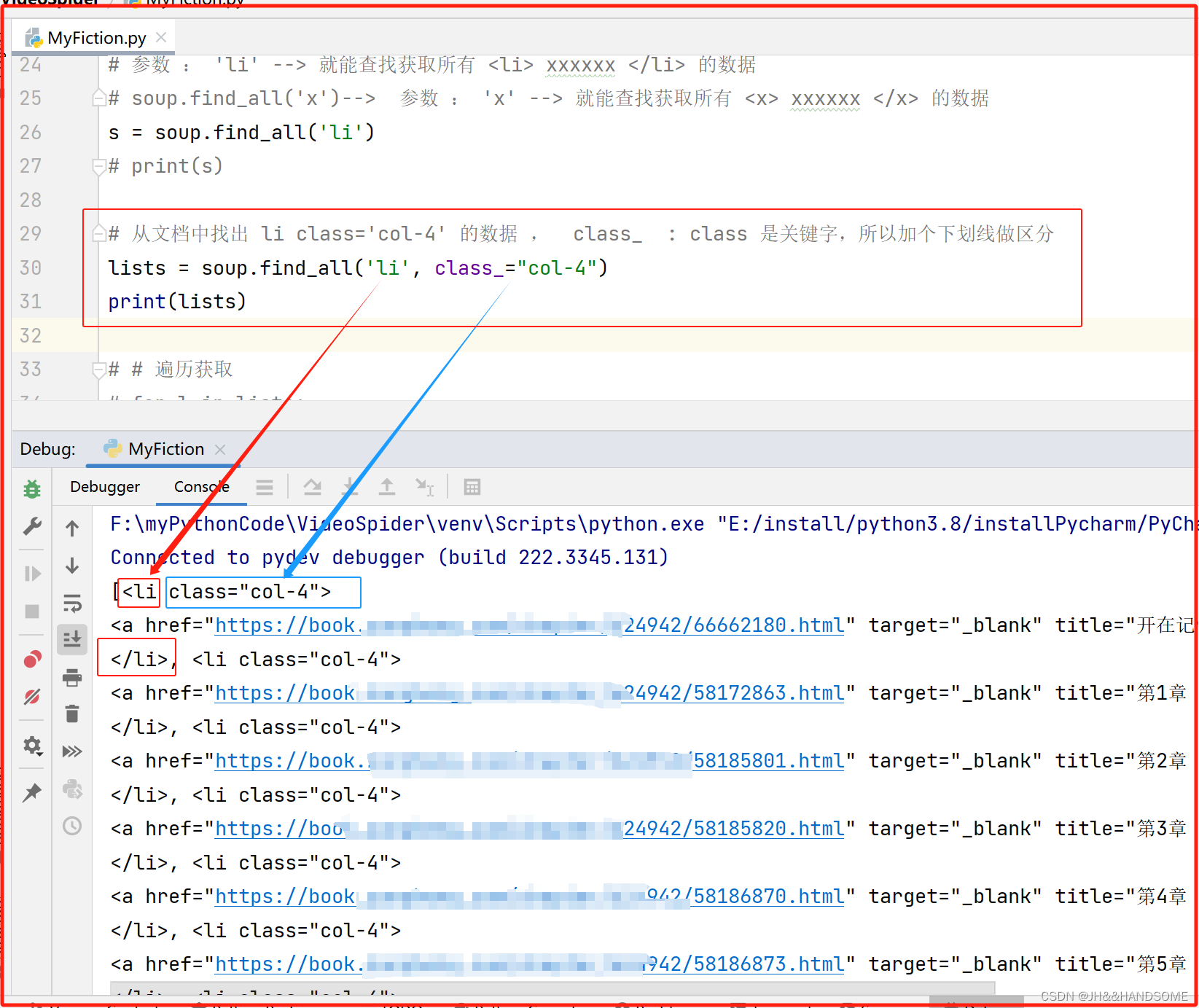
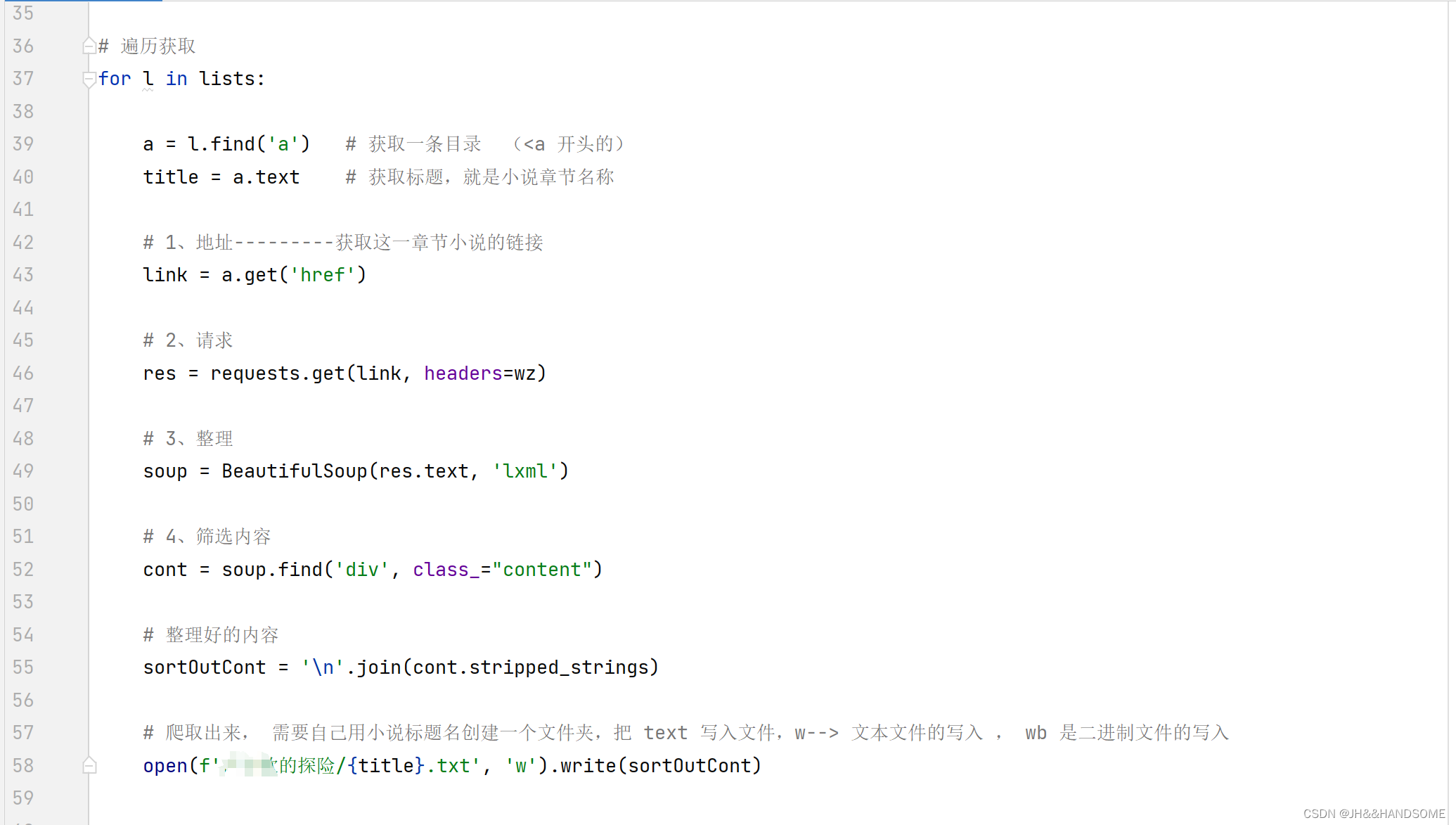
遍历
把筛选的内容进行遍历
获取一条目录 (<a 开头的),就是遍历每一条小说的数据
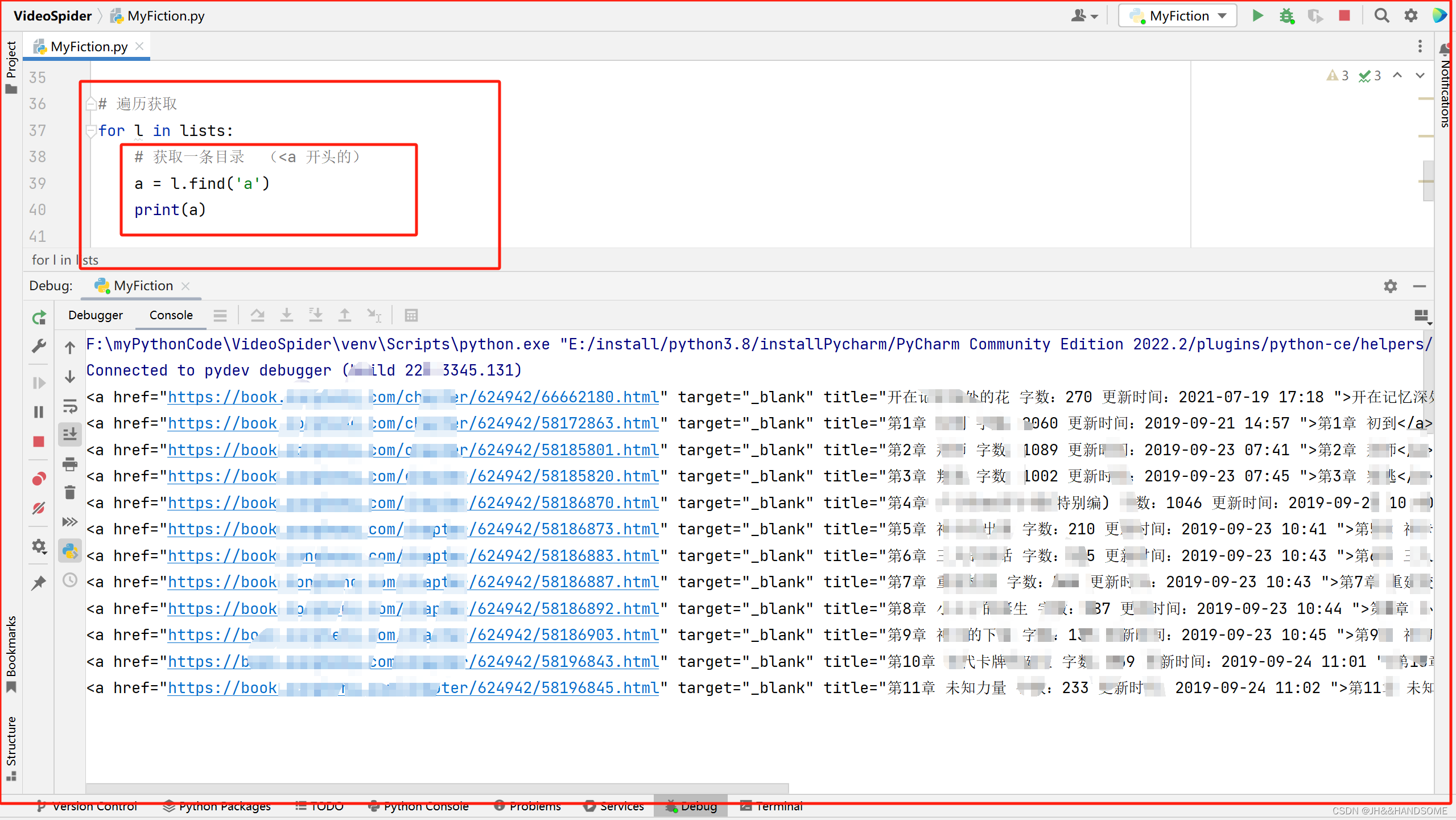
获取小说的章节名称
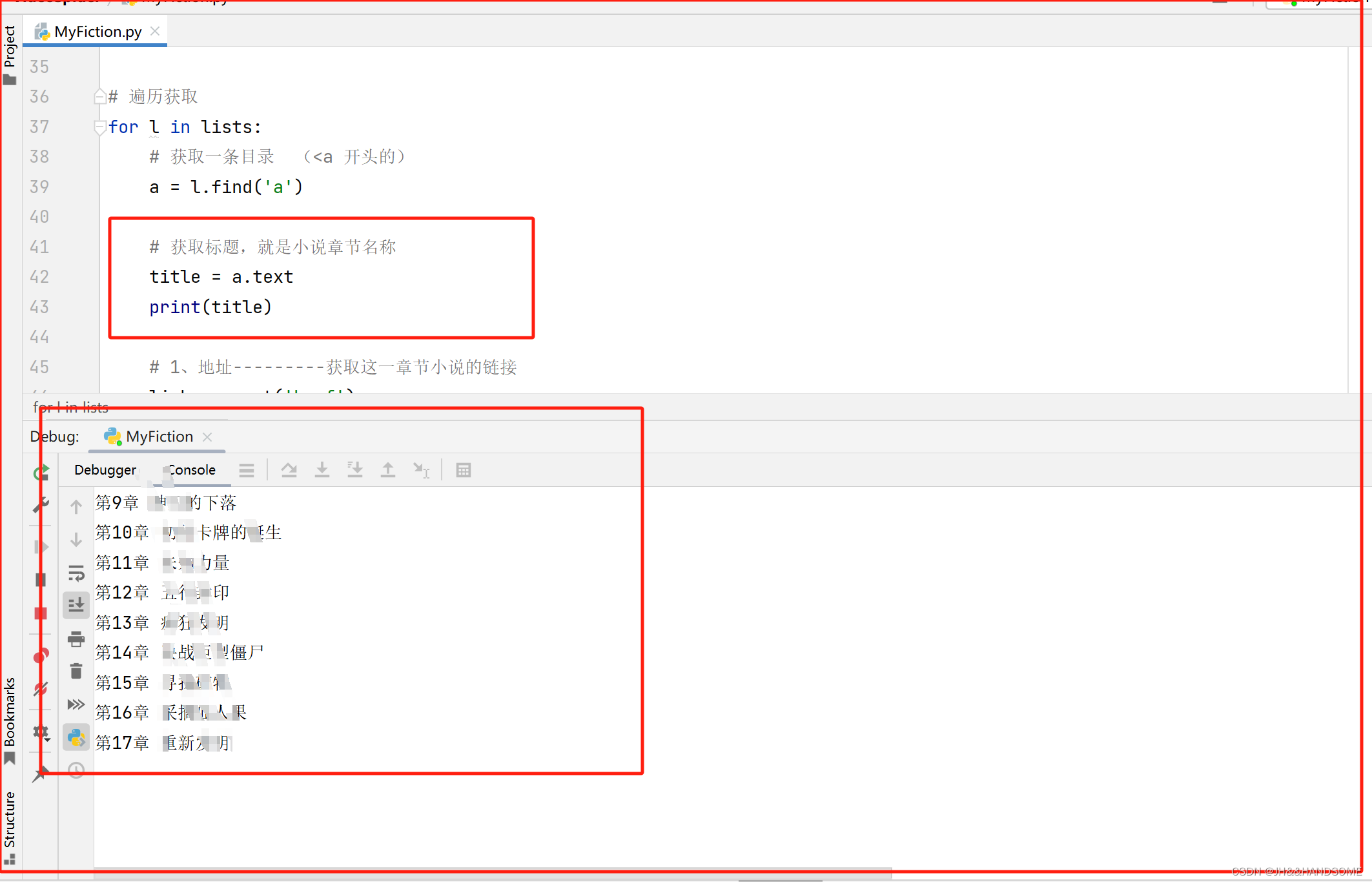
每章小说的链接
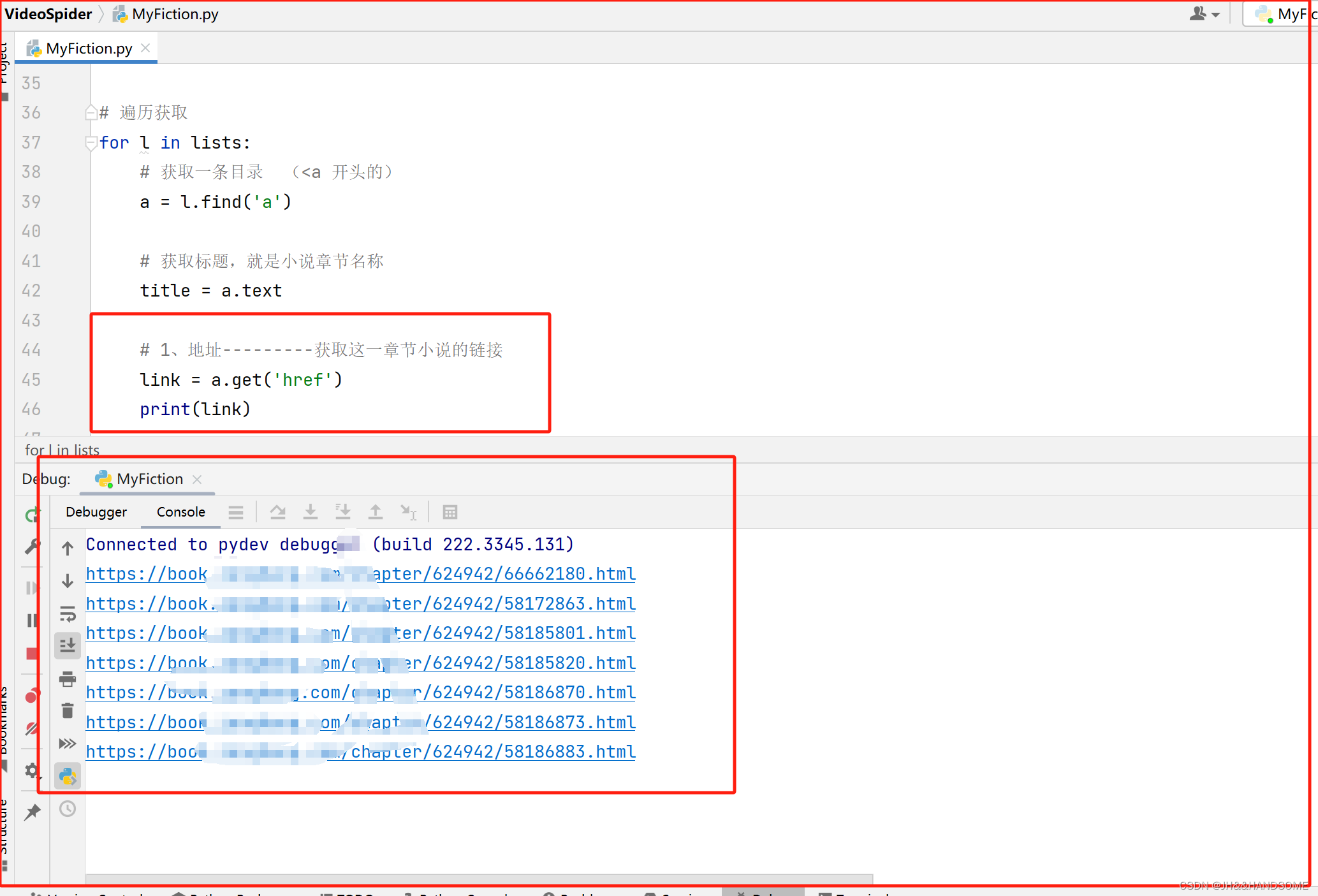
获取请求网址的响应
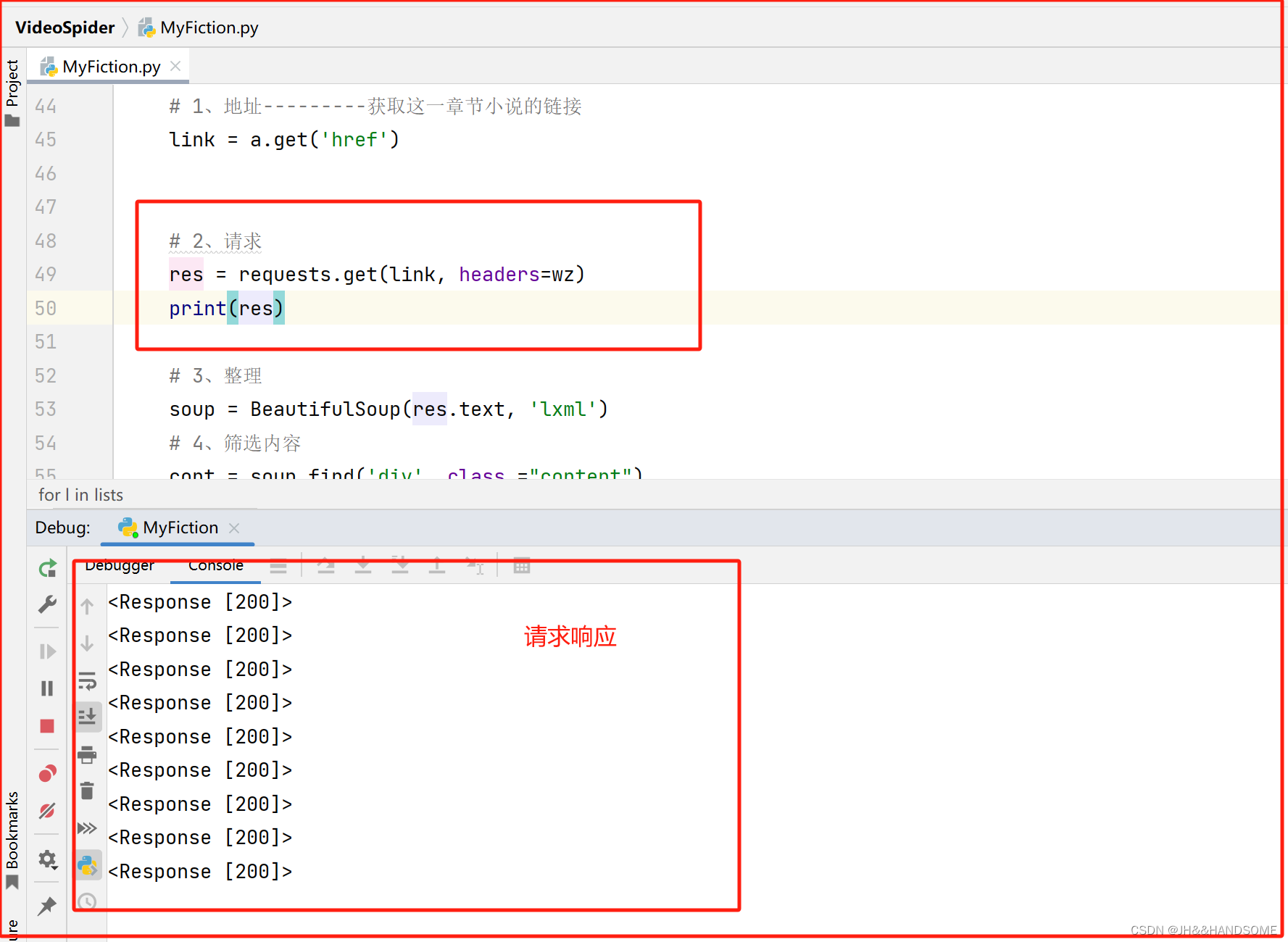
获取小说的内容
获取小说的内容,但是里面还有各种标签,需要进行筛选
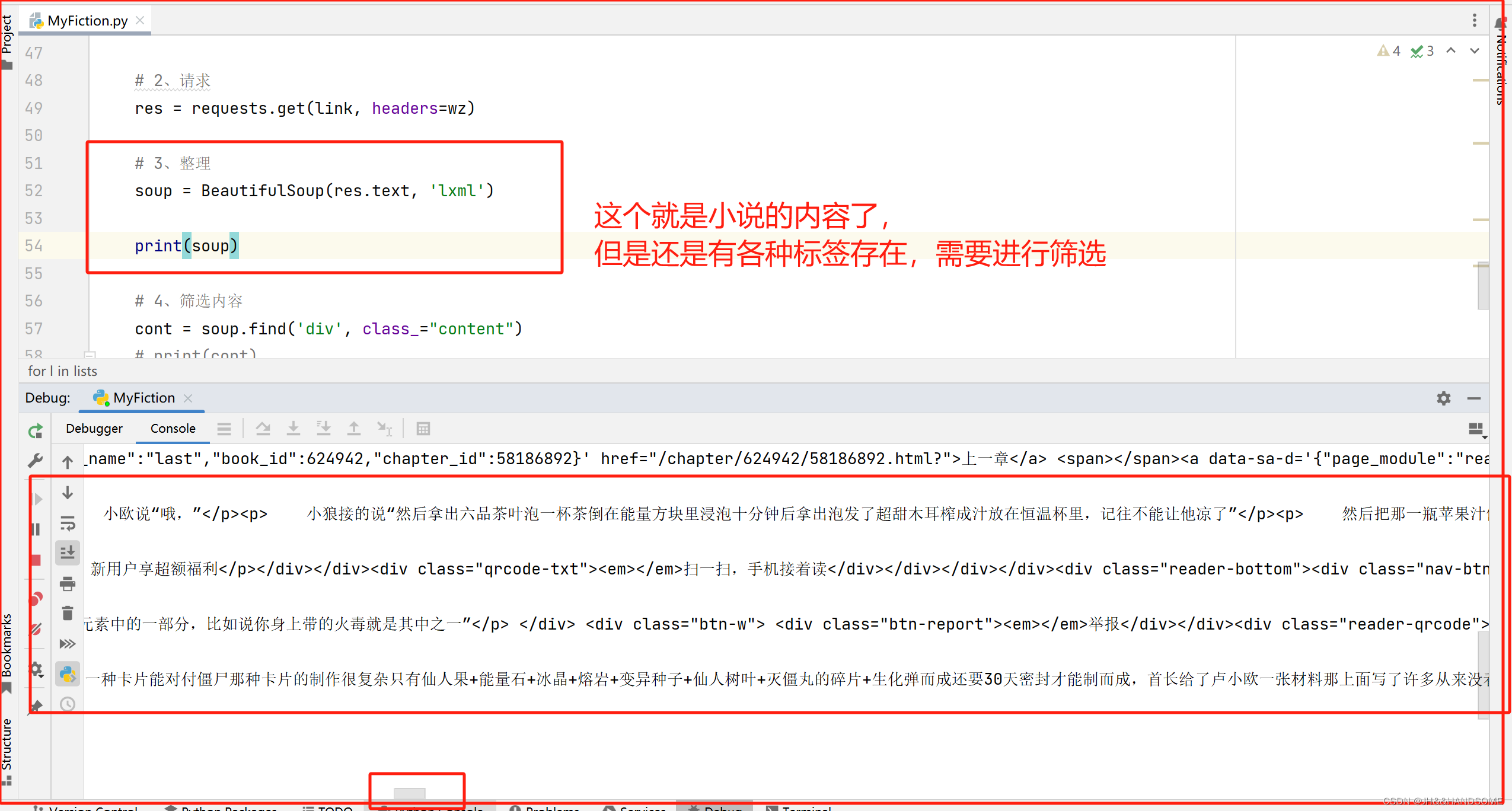
筛选内容
筛选到 <div> 标签了
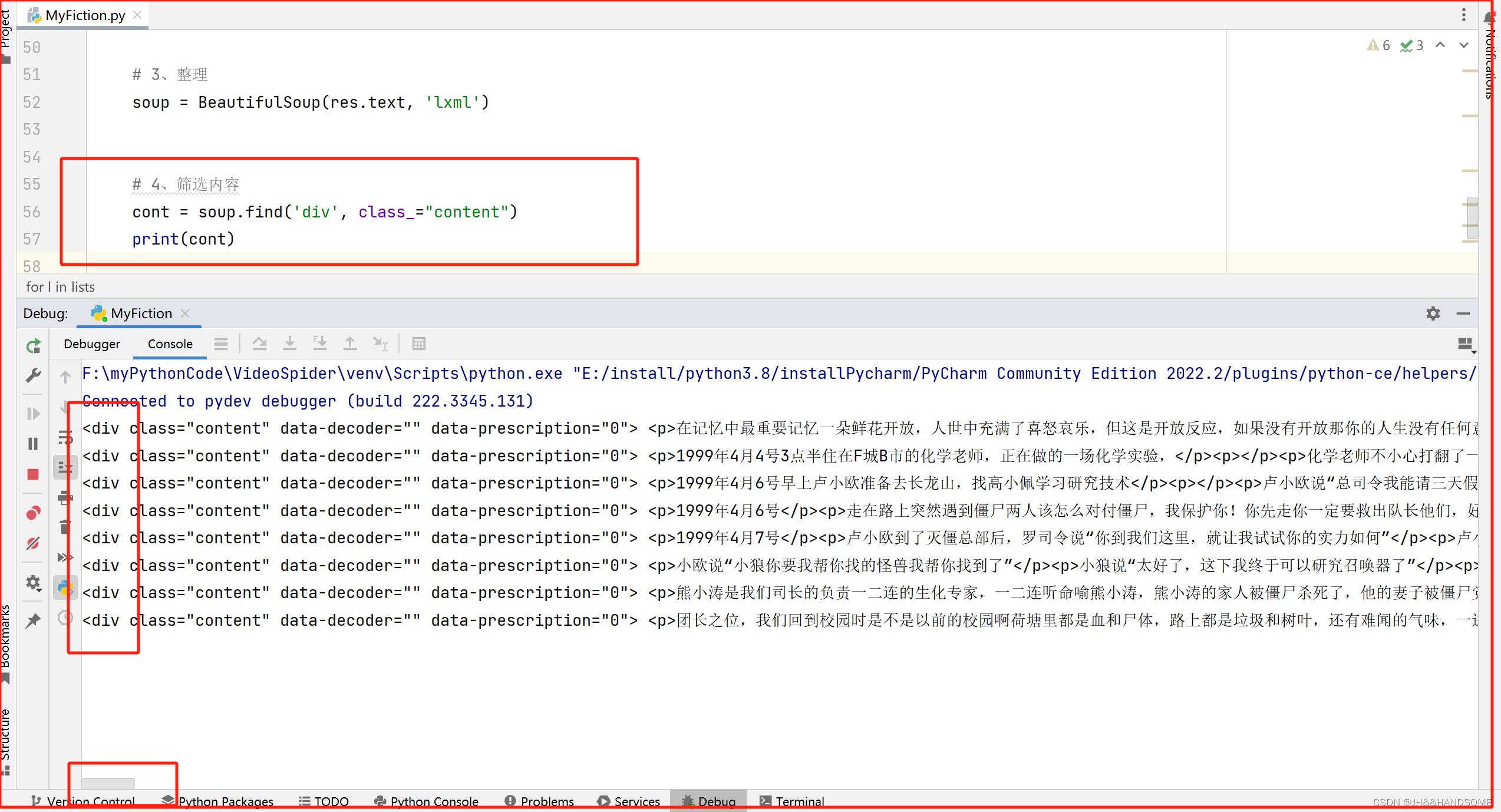
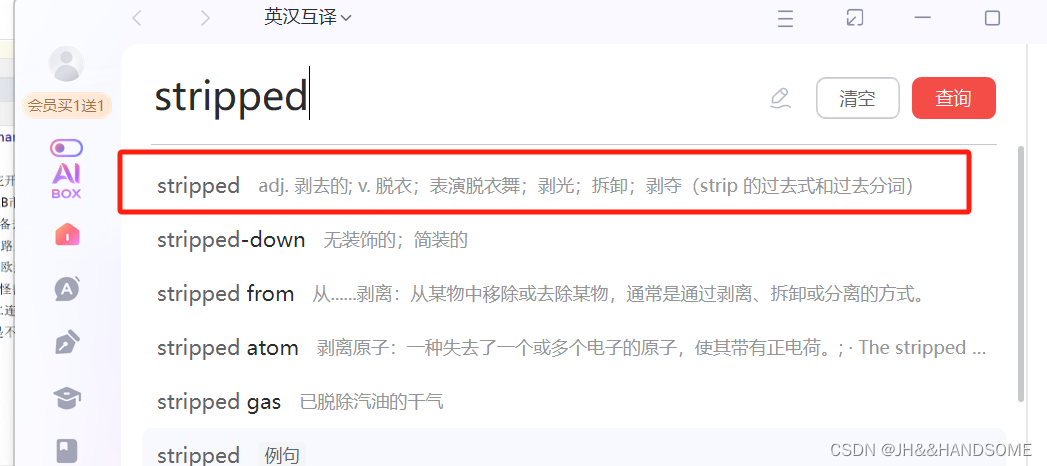
整理内容
把内容再进行整理,去掉 div 标签
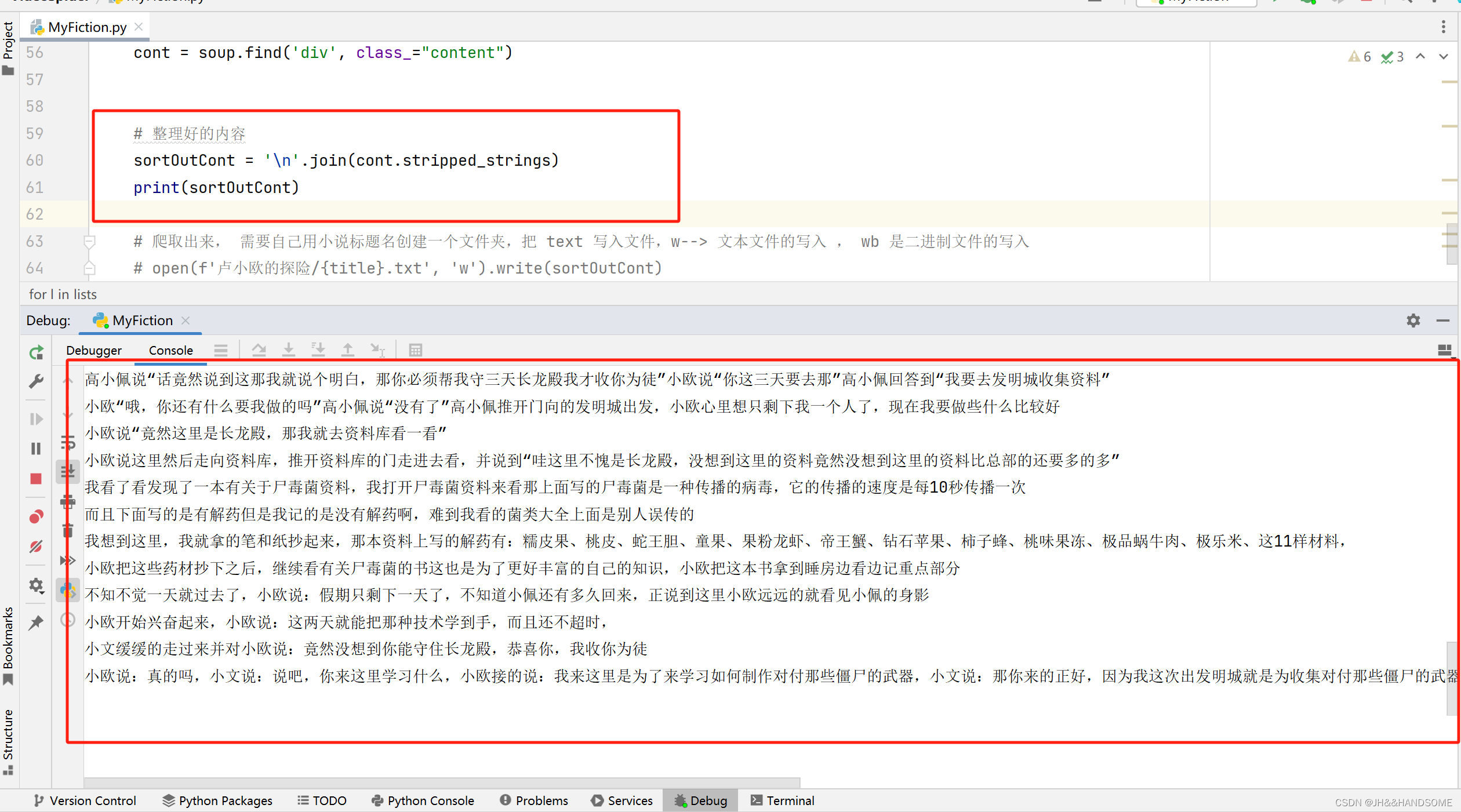
爬取下载到指定文件夹
写入
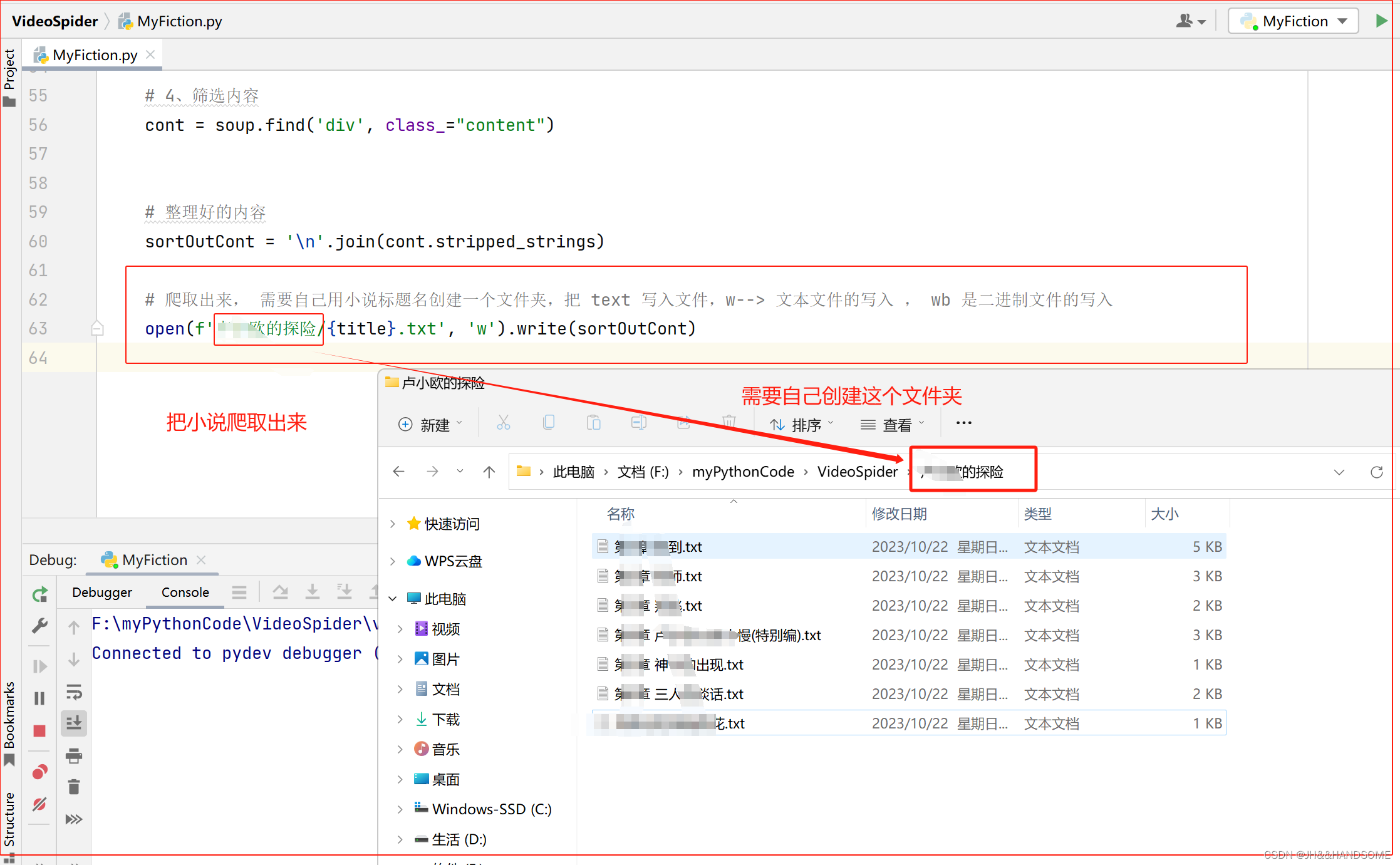
把小说爬取到指定的文件夹位置
完整代码:

# 导入请求模块(完成具体的某一个功能)
import requests
# 把爬虫伪装成一个浏览器,去访问网址
wz = {'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/117.0.0.0 Safari/537.36'}
# 1、地址: 网址:某一篇具体的小说的网址
url = 'https://book.xxxxxxx.com/showchapter/624942.html'
# 2、请求: 请求网址的响应
res = requests.get(url, headers=wz)
# print(res)
# 响应码
# res.status_code
# 响应内容 --- 视频、音乐、图片
# res.content
# 响应的文本数据
# print(res.text)
# 从 bs4 导入 BeautifulSoup
from bs4 import BeautifulSoup
# 3、整理
# 把 res.text 解析成 'lxml' , 相当于把文本原本 text的格式 整理成 lxml格式
soup = BeautifulSoup(res.text, 'lxml')
# print(soup)
# 4、筛选
# 参数 : 'li' --> 就能查找获取所有 <li> xxxxxx </li> 的数据
# soup.find_all('x')--> 参数 : 'x' --> 就能查找获取所有 <x> xxxxxx </x> 的数据
s = soup.find_all('li')
# print(s)
# 筛选:思路是从大到小筛选,实际先筛选小的,找不到再扩大范围筛选
# 从文档中找出 li class='col-4' 的数据 , class_ : class 是关键字,所以加个下划线做区分
lists = soup.find_all('li', class_="col-4")
# print(lists)
# 遍历获取
for l in lists:
# 获取一条目录 (<a 开头的)
a = l.find('a')
# 获取标题,就是小说章节名称
title = a.text
# 1、地址---------获取这一章节小说的链接
link = a.get('href')
# 2、请求
res = requests.get(link, headers=wz)
# 3、整理
soup = BeautifulSoup(res.text, 'lxml')
# 4、筛选内容
cont = soup.find('div', class_="content")
# 整理好的内容
sortOutCont = '\n'.join(cont.stripped_strings)
# 爬取出来, 需要自己用小说标题名创建一个文件夹,把 text 写入文件,w--> 文本文件的写入 , wb 是二进制文件的写入
open(f'xxx的探险/{title}.txt', 'w').write(sortOutCont)
本站大部分文章、数据、图片均来自互联网,一切版权均归源网站或源作者所有。
如果侵犯了您的权益请来信告知我们删除。邮箱:1451803763@qq.com