

python基础爬虫&反爬破解
爬虫初识

简单来说:代替人去模拟浏览器进行网页操作。
爬虫是一种自动地获取网页数据并存储到本地的程序。它的主要作用是获取网站上的数据,这些数据可以用于分析、研究、开发等多种目的。爬虫可以帮助我们获取网站上的数据,而不需要人工浏览和抓取。爬虫的分类主要有通用爬虫和聚焦爬虫。通用爬虫是指搜索引擎和大型web服务提供商的爬虫,它们抓取的是一整张页面数据。聚焦爬虫是针对特定网站的爬虫,它们定向的获取某方面数据的爬虫。
-
Python做爬虫的优势:
- PHP : 对多线程、异步支持不太好
- Java : 代码量大,代码笨重
- C/C++ : 代码量大,难以编写
- Python : 支持模块多、代码简洁、开发效率高 (scrapy框架)
1. HTTP协议与WEB开发
1. 什么是请求头请求体,响应头响应体 2. URL地址包括什么 3. get请求和post请求到底是什么 4. Content-Type是什么
- 1
- 2
- 3
- 4
(1)简介
HTTP协议是Hyper Text Transfer Protocol(超文本传输协议)的缩写,是用于万维网(WWW:World Wide Web )服务器与本地浏览器之间传输超文本的传送协议。HTTP是一个属于应用层的面向对象的协议,由于其简捷、快速的方式,适用于分布式超媒体信息系统。它于1990年提出,经过几年的使用与发展,得到不断地完善和扩展。HTTP协议工作于客户端-服务端架构为上。浏览器作为HTTP客户端通过URL向HTTP服务端即WEB服务器发送所有请求。Web服务器根据接收到的请求后,向客户端发送响应信息。

(2)socket套接字
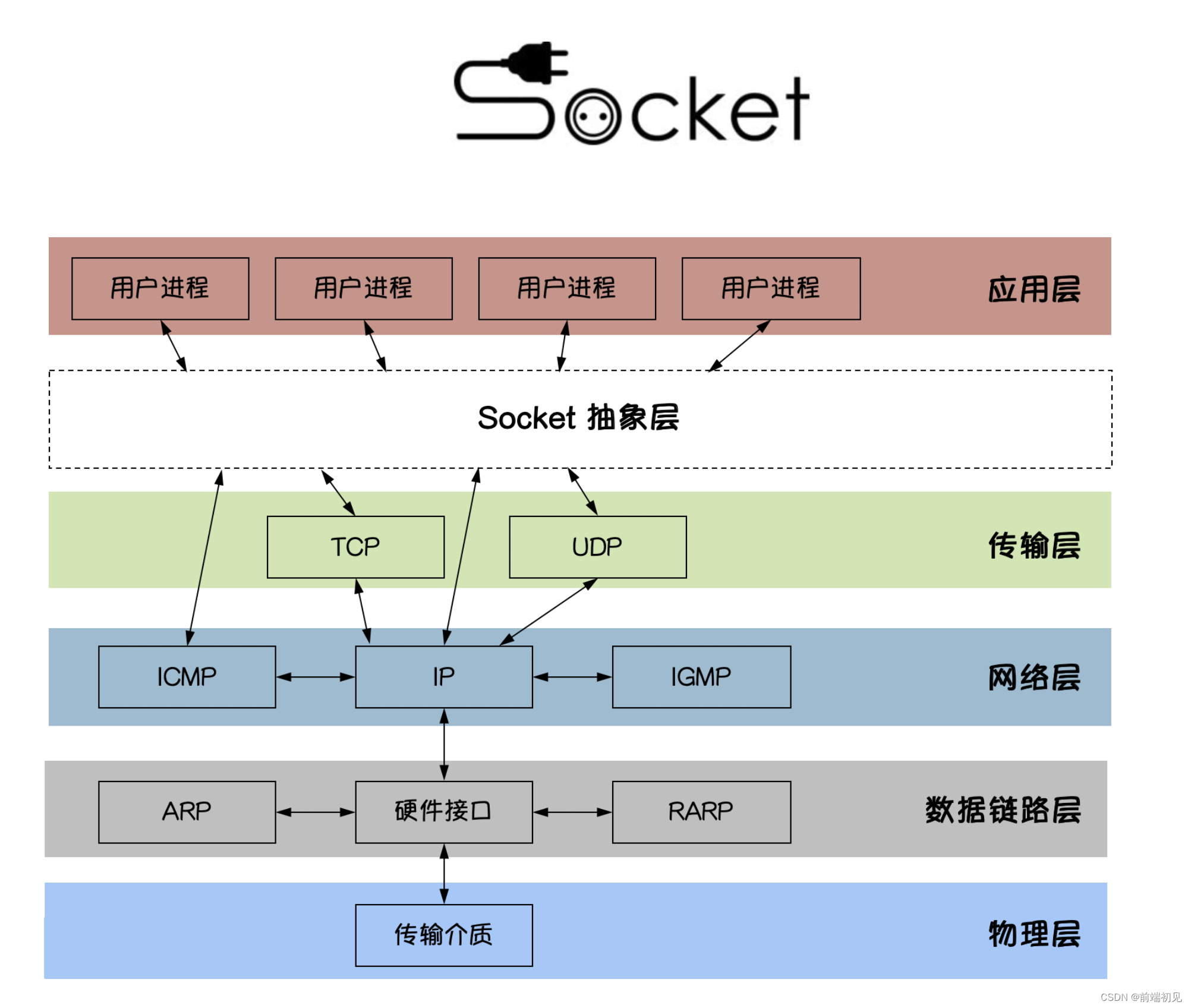
最简单的web应用程序
import socket
sock = socket.socket()
sock.bind(("127.0.0.1", 7777))
sock.listen(3)
print("京东服务器已经启动...")
while 1:
conn, addr = sock.accept()
data = conn.recv(1024)
print("data:", data)
conn.send(
b"HTTP/1.1 200 ok\r\ncontent-type:text/plain\r\n\r\n<h1>alex black girl!</h1><img "
b"src='https://img0.baidu.com/it/u=4011424408,4733765&fm=253&fmt=auto&app=138&f=JPEG?w=500&h=750'>")
conn.close()
基于postman完成测试!
(3)请求协议与响应协议
http协议包含由浏览器发送数据到服务器需要遵循的请求协议与服务器发送数据到浏览器需要遵循的请求协议。用于HTTP协议交互的信被为HTTP报文。请求端(客户端)的HTTP报文 做请求报文,响应端(服务器端)的 做响应报文。HTTP报文本身是由多行数据构成的字文本。
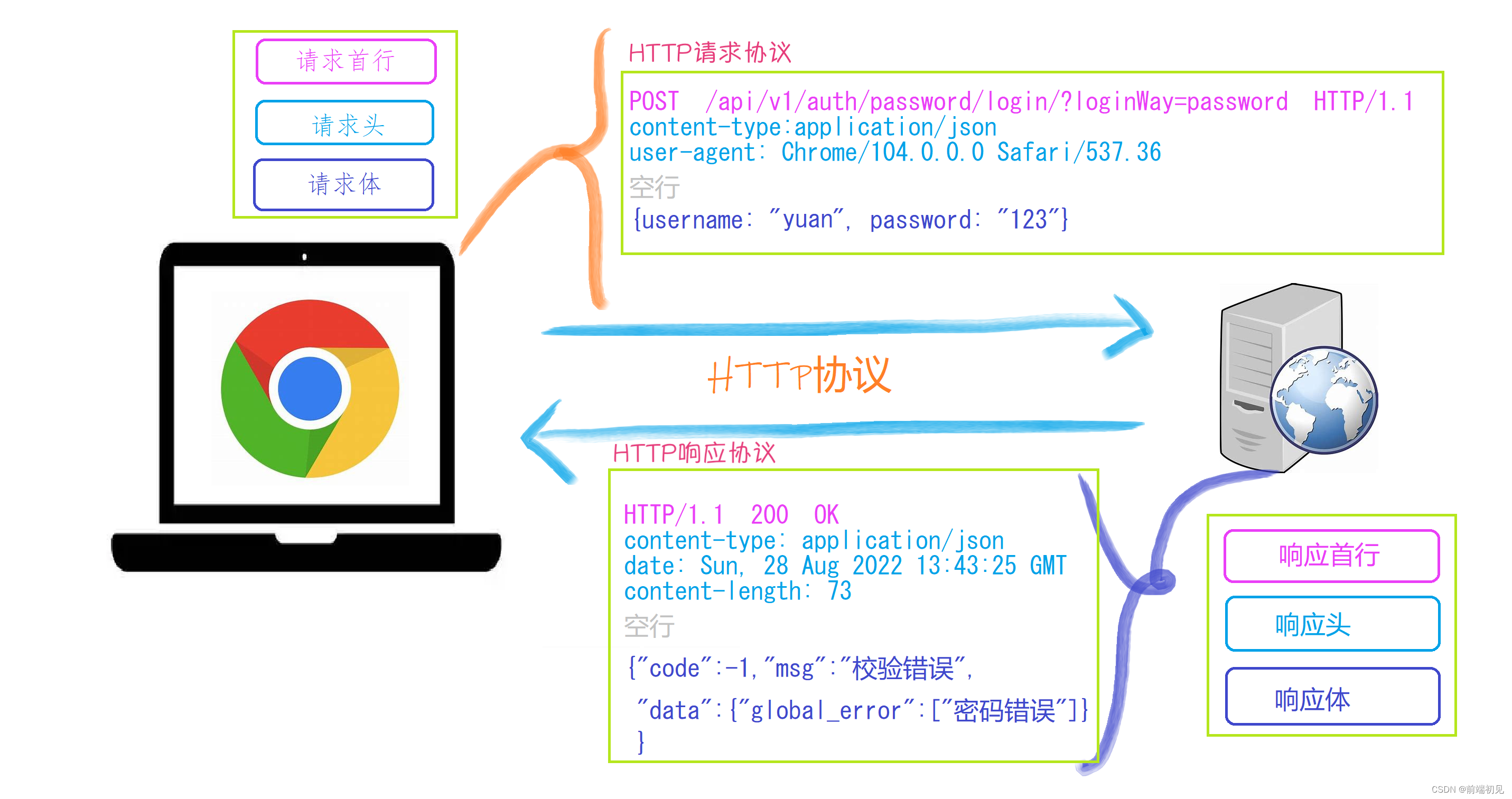
一个完整的URL包括:协议、ip、端口、路径、参数
例如: https://www.baidu.com/s?wd=yuan 其中https是协议,www.baidu.com 是IP,端口默认80,/s是路径,参数是wd=yuan
请求方式: get与post请求
- GET提交的数据会放在URL之后,以?分割URL和传输数据,参数之间以&相连,如EditBook?name=test1&id=123456. POST方法是把提交的数据放在HTTP包的请求体中.
- GET提交的数据大小有限制(因为浏览器对URL的长度有限制),而POST方法提交的数据没有限制
响应状态码:状态码的职 是当客户端向服务器端发送请求时, 返回的请求 结果。借助状态码,用户可以知道服务器端是正常 理了请求,还是出 现了 。状态码如200 OK,以3位数字和原因组成。
2. requests&反爬破解
(1)UA反爬

import requests headers = { "User-Agent": "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/110.0.0.0 Safari/537.36", } res = requests.get( "https://www.baidu.com/", # headers=headers ) # 解析数据 with open("baidu.html", "w") as f: f.write(res.text)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
(2)referer反爬
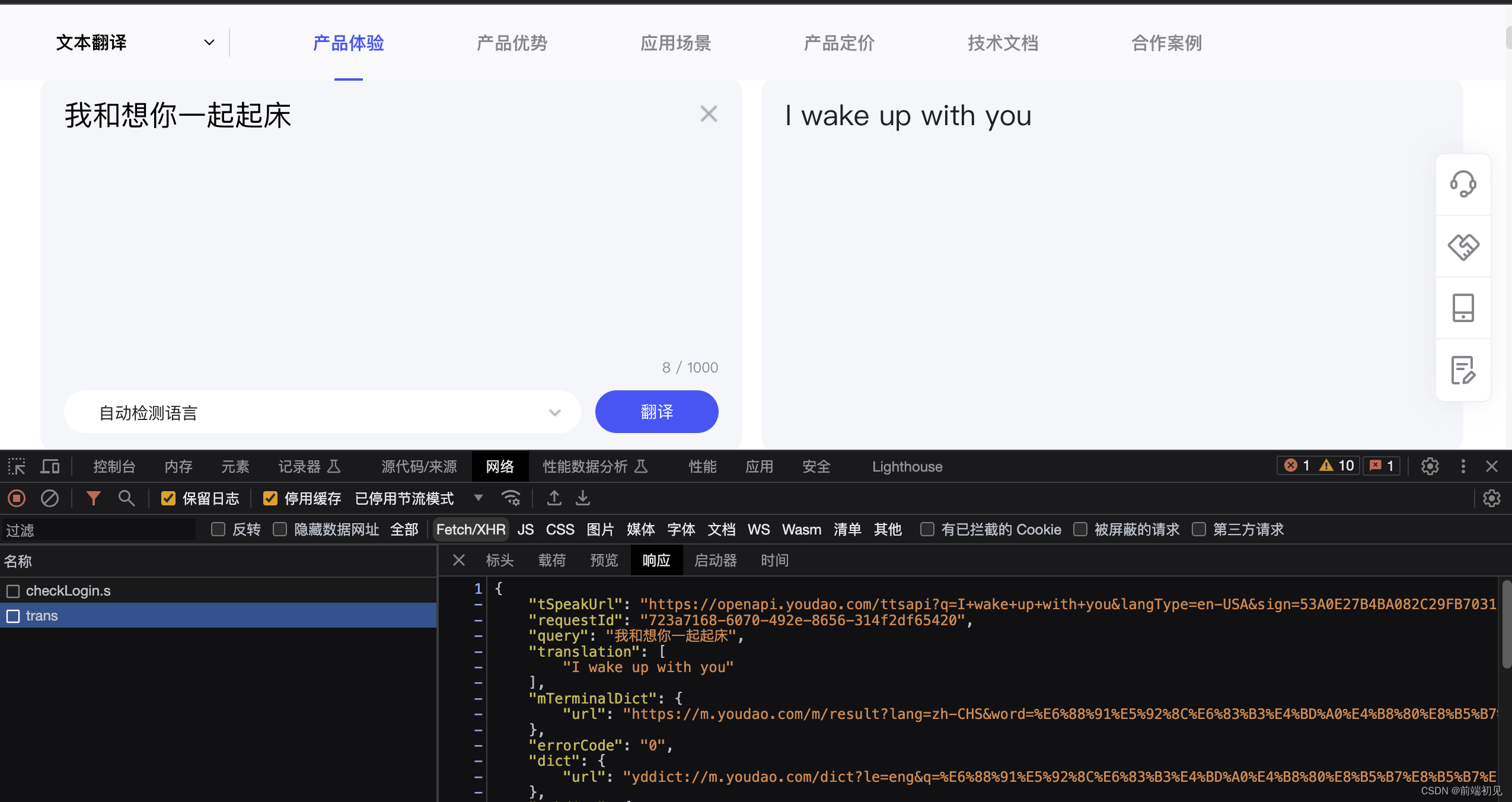
import requests headers = { "User-Agent": "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/110.0.0.0 Safari/537.36", "Referer": "https://movie.douban.com/explore", } res = requests.get( "https://m.douban.com/rexxar/api/v2/movie/recommend?refresh=0&start=0&count=20&selected_categories=%7B%7D&uncollect=false&tags=", headers=headers ) # 解析数据 print(res.text)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
(3)cookie反爬
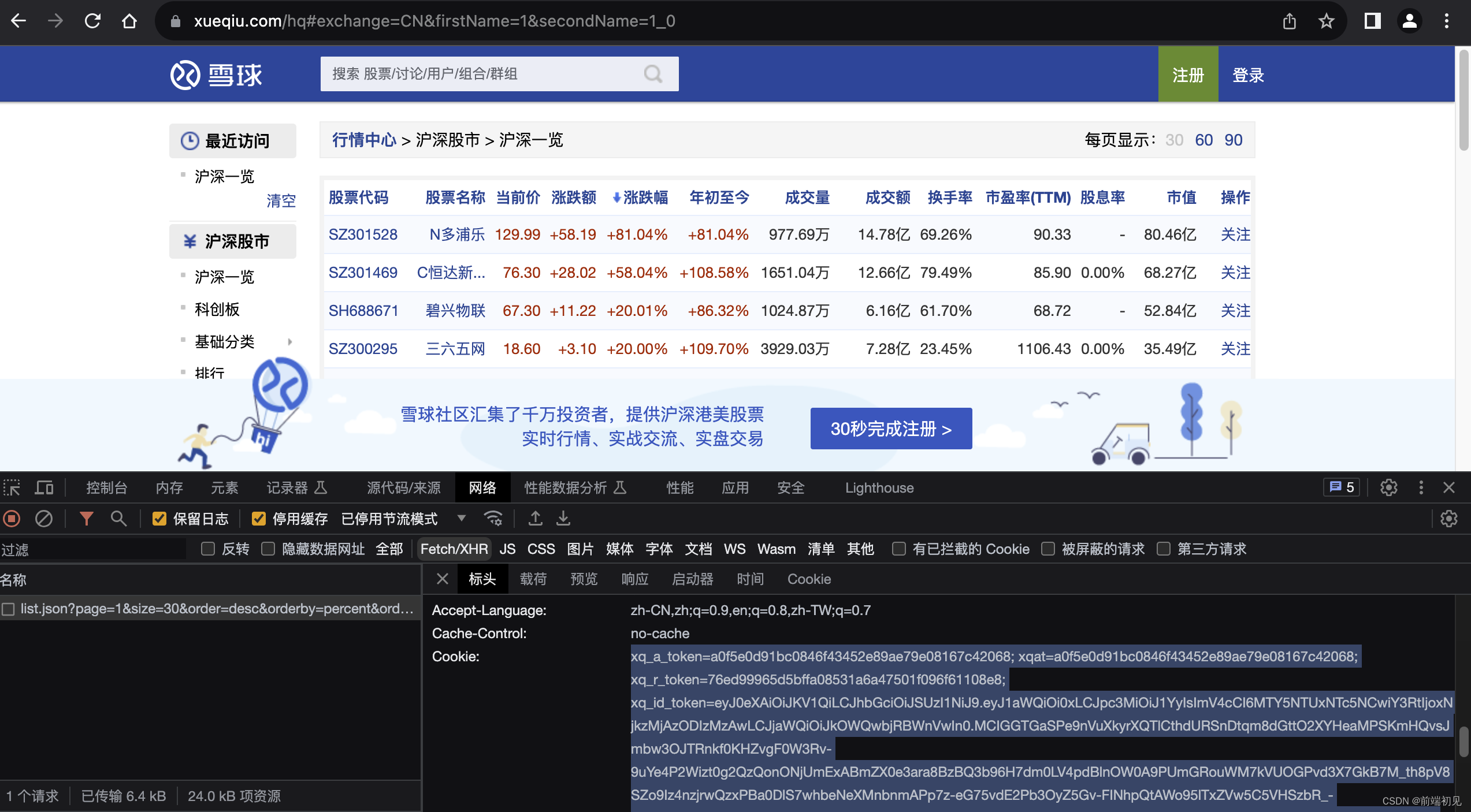
import requests url = "https://stock.xueqiu.com/v5/stock/screener/quote/list.json?page=1&size=30&order=desc&orderby=percent&order_by=percent&market=CN&type=sh_sz" cookie = 'xq_a_token=a0f5e0d91bc0846f43452e89ae79e08167c42068; xqat=a0f5e0d91bc0846f43452e89ae79e08167c42068; xq_r_token=76ed99965d5bffa08531a6a47501f096f61108e8; xq_id_token=eyJ0eXAiOiJKV1QiLCJhbGciOiJSUzI1NiJ9.eyJ1aWQiOi0xLCJpc3MiOiJ1YyIsImV4cCI6MTY5NTUxNTc5NCwiY3RtIjoxNjkzMjAzODIzMzAwLCJjaWQiOiJkOWQwbjRBWnVwIn0.MCIGGTGaSPe9nVuXkyrXQTlCthdURSnDtqm8dGttO2XYHeaMPSKmHQvsJmbw3OJTRnkf0KHZvgF0W3Rv-9uYe4P2Wizt0g2QzQonONjUmExABmZX0e3ara8BzBQ3b96H7dm0LV4pdBlnOW0A9PUmGRouWM7kVUOGPvd3X7GkB7M_th8pV8SZo9Iz4nzjrwQzxPBa0DlS7whbeNeXMnbnmAPp7z-eG75vdE2Pb3OyZ5Gv-FINhpQtAWo95lTxZVw5C5VHSzbR_-z8uqH6DD0xop4_wvKw5LIVwu6ZZ6TUnNFr3zGU9jWqAGgdzcKgO38dlL6uXNixa9mrKOd1OZnDig; cookiesu=431693203848858; u=431693203848858; Hm_lvt_1db88642e346389874251b5a1eded6e3=1693203851; device_id=7971eba10048692a91d87e3dad9eb9ca; s=bv11kb1wna; Hm_lpvt_1db88642e346389874251b5a1eded6e3=1693203857' headers = { 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/109.0.0.0 Safari/537.36', "referer": "https://xueqiu.com/", "cookie": cookie, } res = requests.get(url, headers=headers) print(res.text)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
3. 请求参数
(1)get请求以及查询参数
import requests headers = { "User-Agent": "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/110.0.0.0 Safari/537.36", "Referer": "https://movie.douban.com/explore", } res = requests.get( "https://m.douban.com/rexxar/api/v2/movie/recommend?refresh=0&start=0&count=20&selected_categories=%7B%7D&uncollect=false&tags=", headers=headers, # params={ # 查询 # "count": "20", # "tags": "悬疑" # } ) # 解析数据 print(res.text)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
(2)post请求以及请求体参数

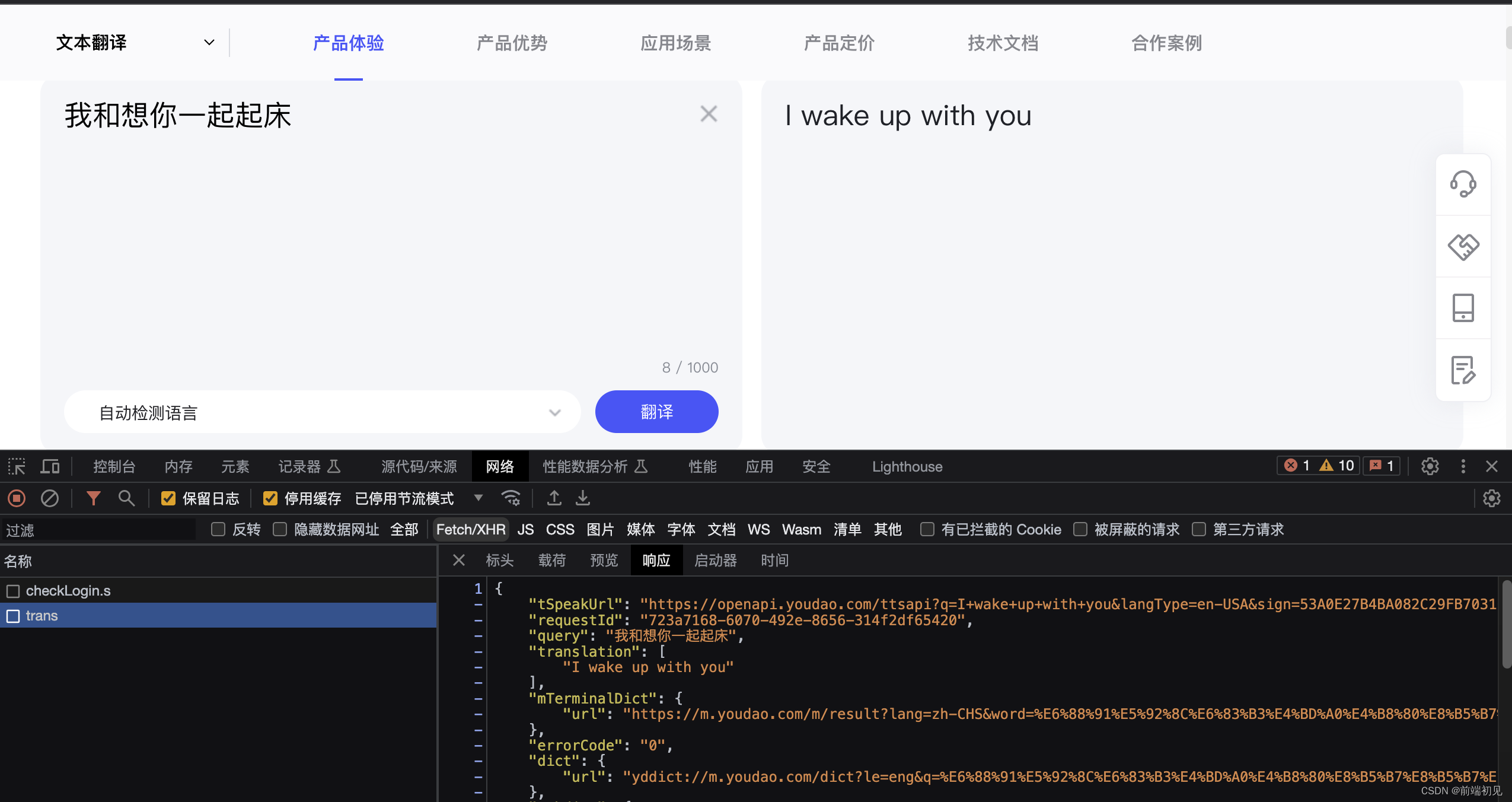
import requests while 1: wd = input("请输入翻译内容:") res = requests.post("https://aidemo.youdao.com/trans?", params={}, headers={}, data={ "q": wd, "from": "Auto", "to": "Auto" }) print(res.json().get("translation")[0])
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
4. 爬虫图片和视频
(1)直接爬取媒体数据流

import requests # (1)下载图片 url = "https://pic.netbian.com/uploads/allimg/230812/202108-16918428684ab5.jpg" res = requests.get(url) # 解析数据 with open("a.jpg", "wb") as f: f.write(res.content) # (2)下载视频 url = "https://vd3.bdstatic.com/mda-nadbjpk0hnxwyndu/720p/h264_delogo/1642148105214867253/mda-nadbjpk0hnxwyndu.mp4?v_from_s=hkapp-haokan-hbe&auth_key=1693223039-0-0-e2da819f15bfb93409ce23540f3b10fa&bcevod_channel=searchbox_feed&pd=1&cr=2&cd=0&pt=3&logid=2639522172&vid=5423681428712102654&klogid=2639522172&abtest=112162_5" res = requests.get(url) # 解析数据 with open("美女.mp4", "wb") as f: f.write(res.content)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
(2)批量爬取数据

import requests import re import os # (1)获取当页所有的img url start_url = "https://pic.netbian.com/4kmeinv/" res = requests.get(start_url) img_url_list = re.findall("uploads/allimg/.*?.jpg", res.text) print(img_url_list) # (2)循环下载所有图片 for img_url in img_url_list: res = requests.get("https://pic.netbian.com/" + img_url) img_name = os.path.basename(img_url) with open(img_name, "wb") as f: f.write(res.content)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
总结
如果这篇【文章】有帮助到你??,希望可以给我点个赞??,创作不易,如果有对前端端或者对python感兴趣的朋友,请多多关注??????,咱们一起探讨和努力!!!
????? 个人主页 : 前端初见
本站大部分文章、数据、图片均来自互联网,一切版权均归源网站或源作者所有。
如果侵犯了您的权益请来信告知我们删除。邮箱:1451803763@qq.com