
在当今数字时代,构建高效、可扩展的Web应用程序是开发者们的一项重要任务。Python,作为一种简洁、强大的编程语言,为Web开发提供了丰富的工具和框架。

Python 语言拥有丰富的数据可视化库,其中 Plotly 是一款流行的工具,提供了绘制高质量三维图形的功能。
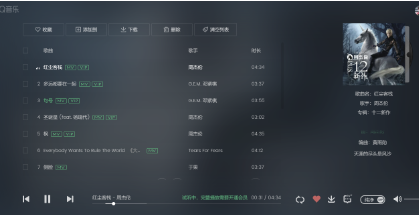
小白易懂手把手教你操作,qq音乐,网易云音乐,酷狗音乐,酷我音乐等等一系列音乐手把手教你爬取下载

本文介绍两种python的打包方案,使用pyinstaller和nuitka打包成exe

数据预处理是数据准备阶段的一个重要环节,主要目的是将原始数据转换成适合机器学习模型使用的格式,数据预处理可以显著提高机器学习模型的性能和准确度

爬虫是一种自动地获取网页数据并存储到本地的程序

本文将实现豆瓣Top250电影数据的简单爬取。

爬取小说(解决遇到cookie验证爬取不了的问题)

NameError: name ‘python‘ is not defined异常的解决方法
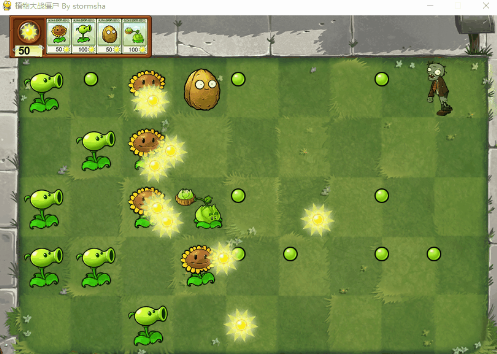
Python 植物大战僵尸

