

Python爬取小说(解决遇到cookie验证爬取不了的问题)
前段时间五一放假,在家没事干,在哔哩哔哩上瞎看,发现一个搞笑视频合集不错,闲来无事正好晚上催眠用,名称叫《我靠打爆学霸兑换黑科技》,里面的男主角生为一个高中生学习天赋惊人,各种逆袭外挂的人生,看的令人神往。
链接如下:
雯锐动画投稿视频-雯锐动画视频分享-哔哩哔哩视频 (bilibili.com)
https://space.bilibili.com/357072740/video
可惜动画更新的很慢,所以我直接搜索看后面章节的小说。经常看小说的都知道,看免费小说网站的广告多,我一般都是花个半天写了个脚本,爬取下来看,所以也就有了这篇文章。网站界面如下:
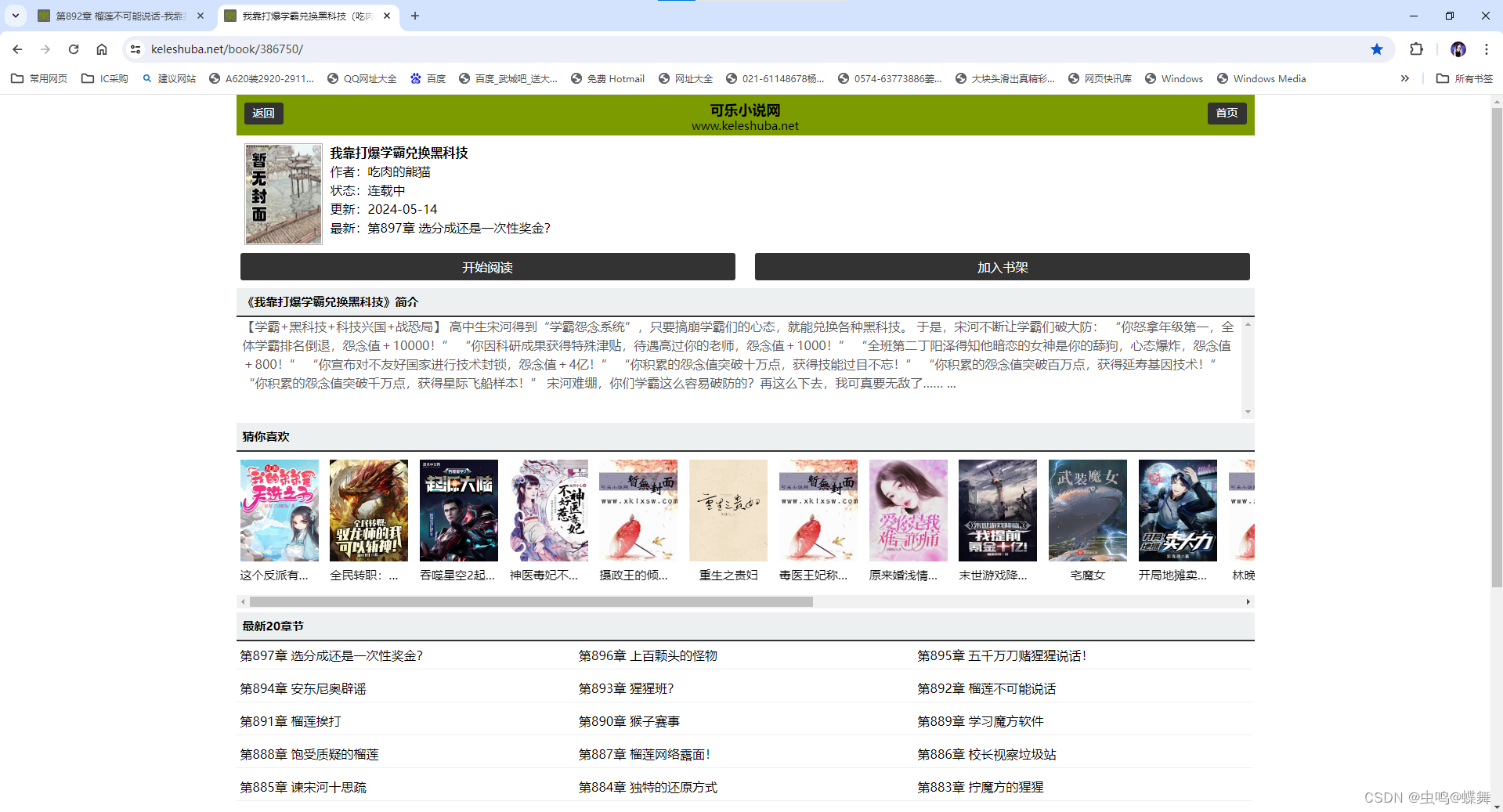
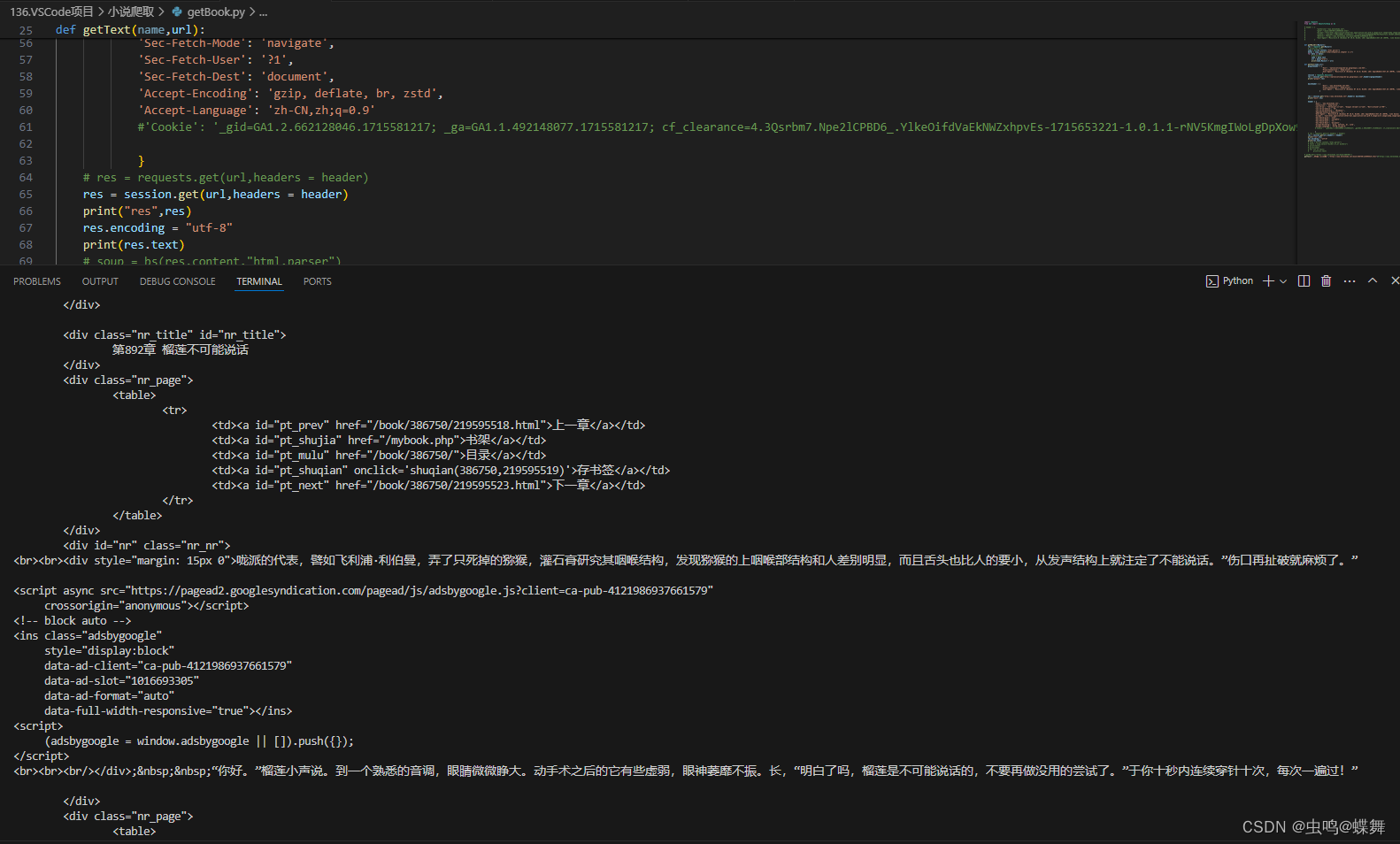
本来应该是很简单的脚本,但是这个网站对每一章的小说有cookie验证,导致用传统的requests库爬不完整,服务器发现cookie不正确后,会把缺失的html返回给我。如下图,可以看到连requests返回的body都是不对的,更别提后面的了。
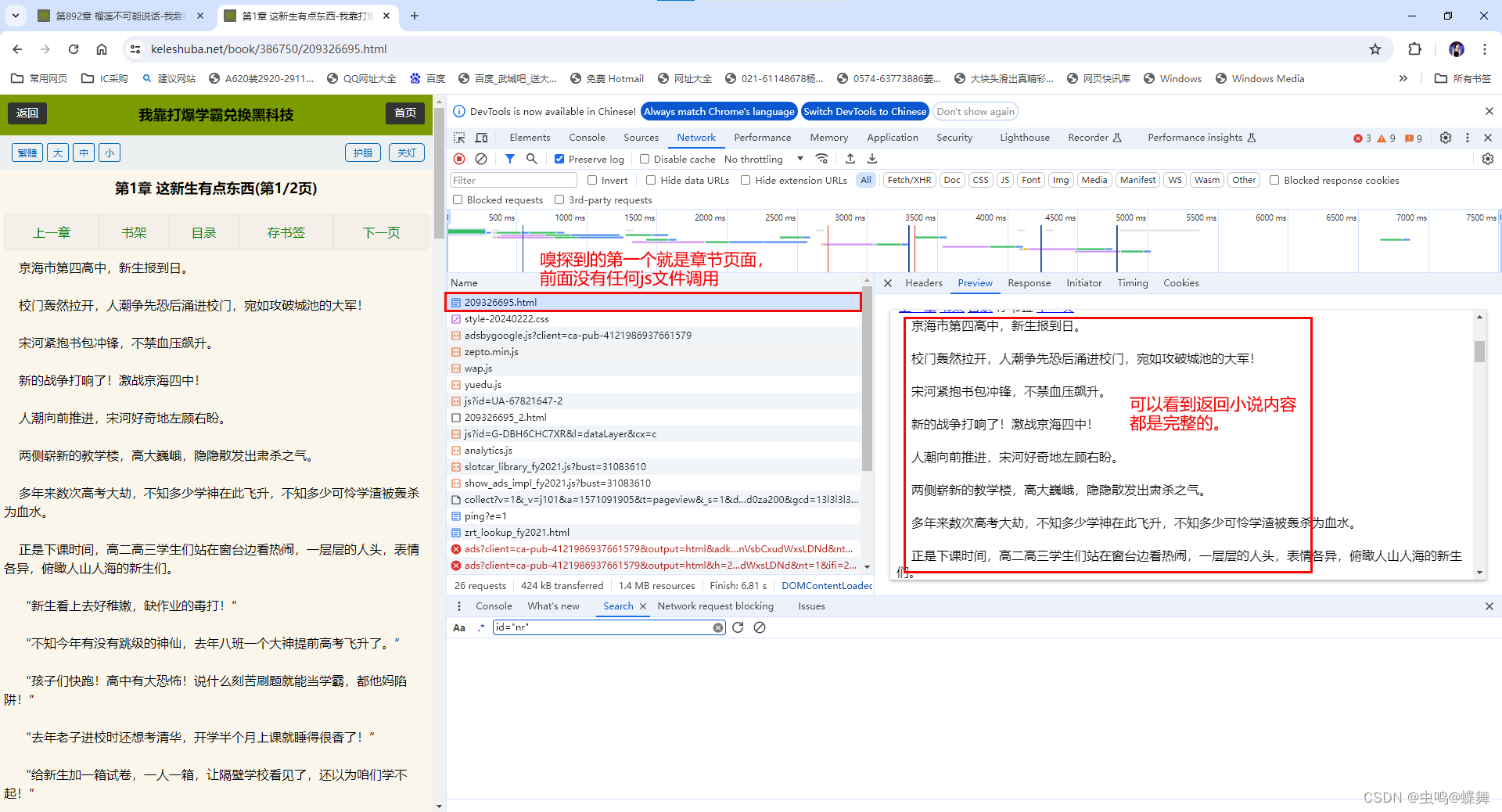
使用chrome浏览器的开发者工具(F12快捷键打开),发现打开单个章节前面并没有javascript文件调用(也就是说小说内容不是通过javascript生成的),也没有其他网址调用,直接就返回了html超链接文本,如下:
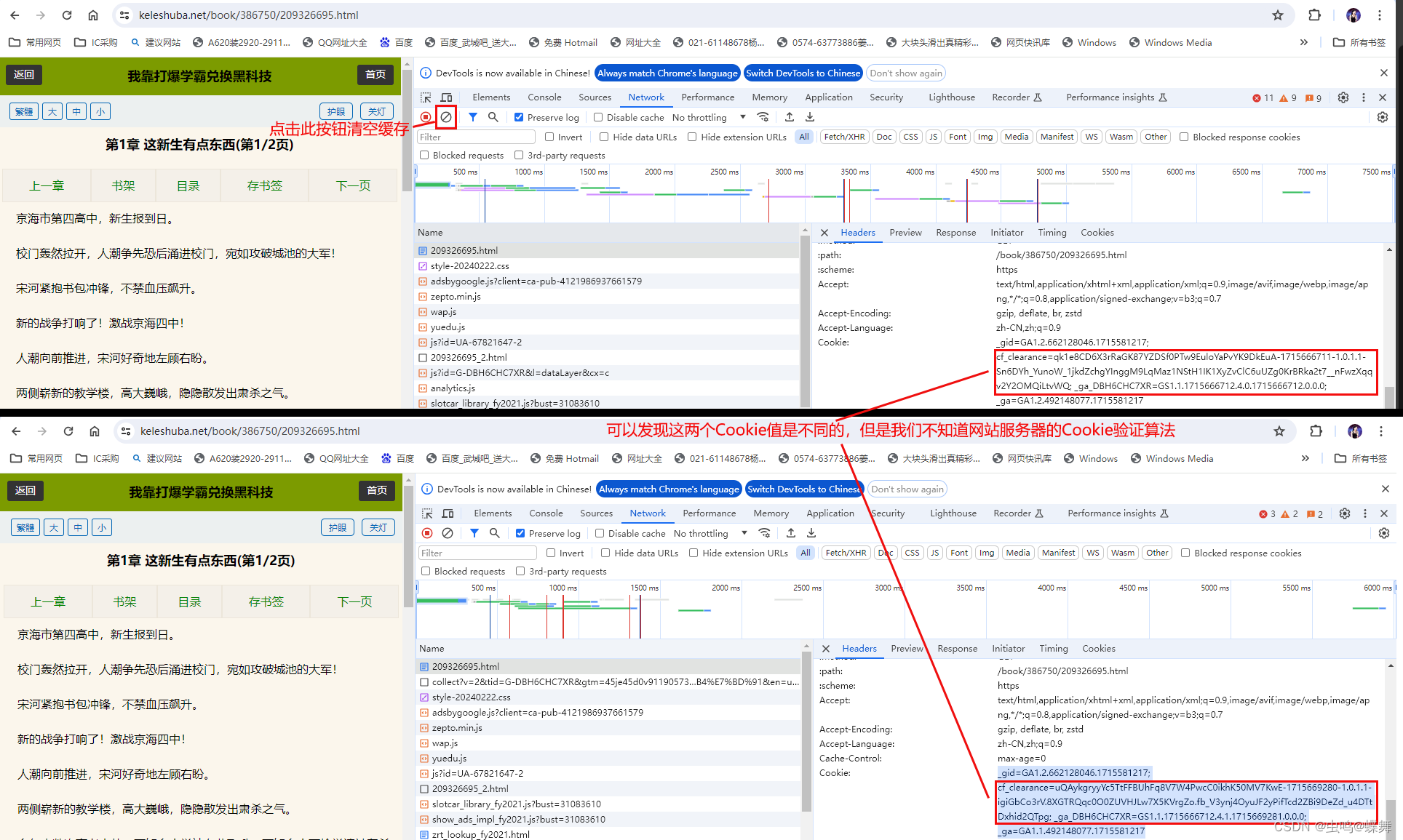
 尝试了使用requests加headers请求头、session等方法都失败。因为网站有cookie验证,如果用requests库模拟有点难实现,如下图:
尝试了使用requests加headers请求头、session等方法都失败。因为网站有cookie验证,如果用requests库模拟有点难实现,如下图:
既然有cookie校验,那就使用selenium和ChromeDriver来爬取即可。不了解的朋友,可用把selenium想象成一个可以用python代码控制的Chrome浏览器,它是有界面的(我喜欢叫它有头版爬虫),requests相对的就是无头版爬虫(headless),通过下面的方法可以安装。
安装 Selenium 需要进行以下几个步骤:
安装 Selenium 包
安装浏览器驱动程序(例如 ChromeDriver 或 GeckoDriver)
以下是详细步骤:
1. 安装 Selenium 包
你可以使用pip来安装 Selenium 包。打开终端或命令提示符,然后运行以下命令:
pip install selenium
2. 安装浏览器驱动程序
Selenium 需要一个浏览器驱动程序来控制浏览器。常用的浏览器驱动程序有:
ChromeDriver:用于控制 Google Chrome 浏览器
GeckoDriver:用于控制 Mozilla Firefox 浏览器
安装 ChromeDriver
- 访问 https://chromedriver.chromium.org/downloads。
- 根据你的操作系统下载相应版本的 ChromeDriver。
- 解压缩下载的文件,将可执行文件放在一个目录中,并将该目录添加到系统的PATH环境变量中。
或者,你可以使用webdriver-manager自动安装和管理 ChromeDriver:
pip install webdriver-manager
使用webdriver-manager来自动下载和使用 ChromeDriver,示例代码如下:
from selenium import webdriverfrom selenium.webdriver.chrome.service import Service
from webdriver_manager.chrome import ChromeDriverManager
# 自动下载和启动 ChromeDriver
service = Service(ChromeDriverManager().install())
driver = webdriver.Chrome(service=service)
# 打开一个网页
driver.get('https://www.baidu.com')
# 关闭浏览器
driver.quit()
我们通过上面的分析可以知道小说都在网页元素id为"nr"的里面,所以使用上面的selenium例子,我们可以编写如下代码启动selenium,打开我们需要的小说章节,并保存下小说内容:
from selenium import webdriverfrom selenium.webdriver.chrome.service import Service
from webdriver_manager.chrome import ChromeDriverManager
from selenium.webdriver.common.by import By
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
import time
# 自动下载和启动 ChromeDriver
service = Service(ChromeDriverManager().install())
driver = webdriver.Chrome(service=service)
def getText(name,url):
starttime = time.time()
# 打开一个网页
driver.get(url)
try:
element = WebDriverWait(driver, 10).until(EC.presence_of_element_located((By.ID,'nr')))
txts = element.text.replace("\n","").replace(" ","\n")# 这两句是格式化小说文本,输出到txt文档里保存
txts = txts + "\n" if txts[1] == "第" else name + txts + "\n\n"
with open("我靠打爆学霸兑换黑科技.txt",'a+',encoding="utf-8") as f:
f.write(txts)
f.close()
endtime = time.time()
print(name,"已完成!",f"耗时{(endtime - starttime)}秒.")
except TimeoutError:
print("Time out!")
if __name__ == "__main__":
getText("第1章 这新生有点东西(第1/2页)","https://www.keleshuba.net/book/386750/219595519.html")
这里最关键的一句就是如下:
element = WebDriverWait(driver, 10).until(EC.presence_of_element_located((By.ID,'nr')))
这行代码使用了 Selenium 的显式等待(Explicit Wait)功能,以确保在执行后续操作之前,页面上特定的元素已经加载并存在。下面是逐步解释:
1. WebDriverWait(driver, 10)
WebDriverWait 是一个等待类,它会反复检查某个条件直到它成立(例如,某个元素存在),或者达到最大等待时间。
driver 是你的 WebDriver 实例,用于控制浏览器。
10 是最大等待时间(以秒为单位)。在这段时间内,WebDriver 会每隔一段时间(10秒)检查一次条件是否成立。
2. .until(EC.presence_of_element_located((By.ID, 'nr')))
.until 方法接受一个等待条件,在条件满足之前会一直等待。
EC 代表 expected_conditions 模块,包含了一组预定义的条件供显式等待使用。
EC.presence_of_element_located 是一个条件,表示要等待某个元素出现在 DOM 中,但不一定可见。
(By.ID, 'nr') 是定位元素的方式:
By.ID 指定使用元素的 ID 属性来查找。
'nr' 是目标元素的 ID 值
所以上面简单说,就是每10s一次检查id为"nr"的元素是否出现。
然后我们分析下小说的章节目录页,这个没有cookie校验,普通的requests就能实现,我们把里面的章节名和网址拿出来,就能传入上面的getText获得每一章的小说内容。
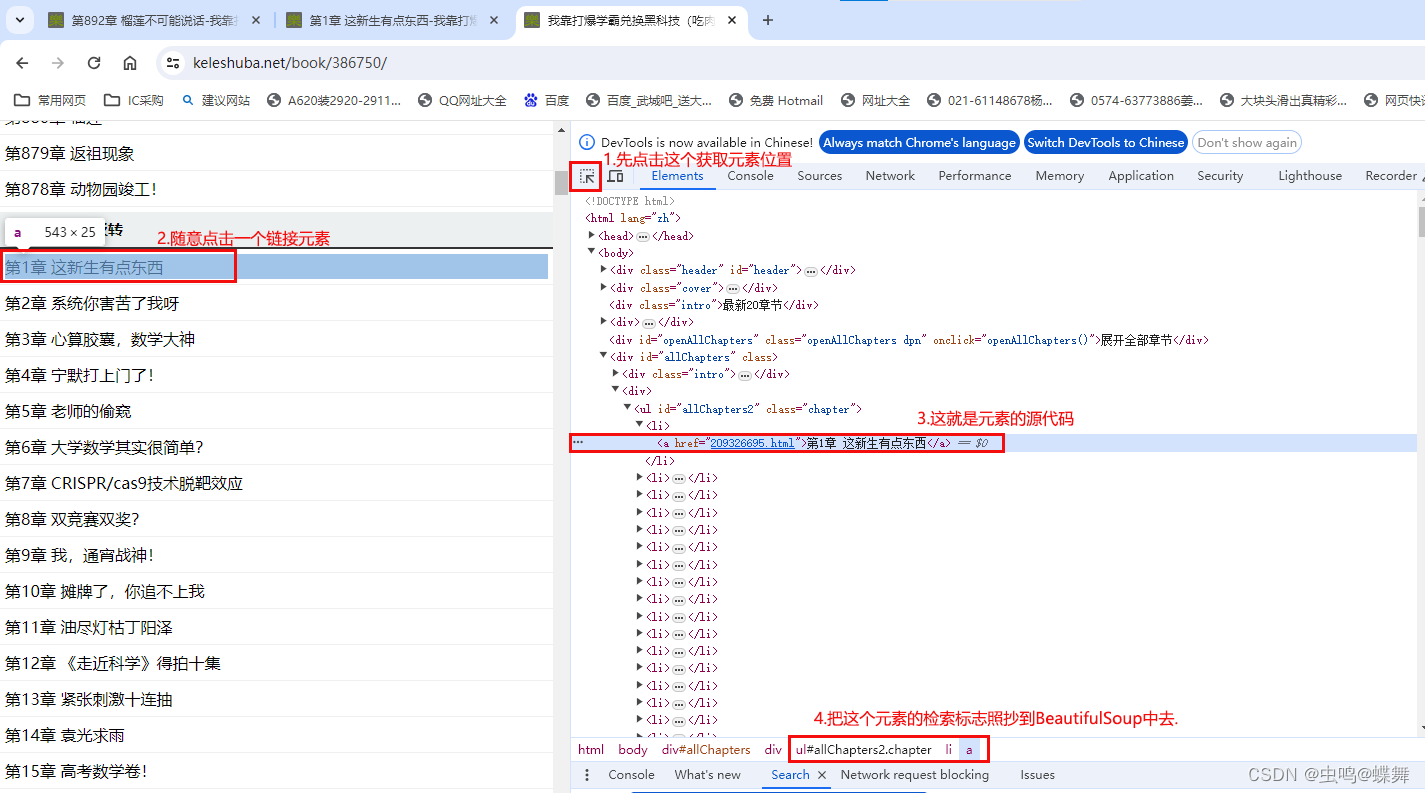
代码如下:
import requestsfrom bs4 import BeautifulSoup as bs
def getMainUrl(Mainurl):
res = requests.get(Mainurl)
soup = bs(res.content,"html.parser")
datas = soup.select("ul#allChapters2.chapter li a")
for data in datas:
name = data.text
url = data["href"]
print(name,Mainurl + url)
getText(name,Mainurl + url)
if __name__ == "__main__":
getMainUrl("https://www.keleshuba.net/book/386750/")
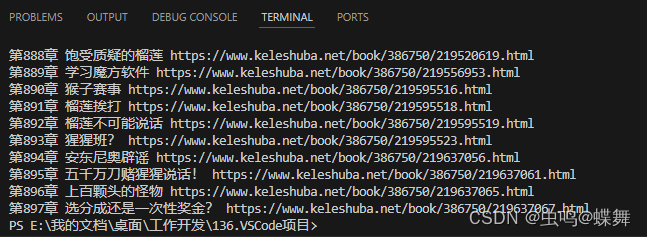
代入getText前,先用print输出看看章节名称和网址对不对,如下图:
最后我们把所有的东西都拼接到一起,完整代码如下:
import requestsfrom bs4 import BeautifulSoup as bs
from selenium import webdriver
from selenium.webdriver.chrome.service import Service
from webdriver_manager.chrome import ChromeDriverManager
from selenium.webdriver.common.by import By
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
import time
# 自动下载和启动 ChromeDriver
service = Service(ChromeDriverManager().install())
driver = webdriver.Chrome(service=service)
def getMainUrl(Mainurl):
res = requests.get(Mainurl)
soup = bs(res.content,"html.parser")
datas = soup.select("ul#allChapters2.chapter li a")
for data in datas:
name = data.text
url = data["href"]
getText(name,Mainurl + url)
def getText(name,url):
starttime = time.time()
# 打开一个网页
driver.get(url)
try:
element = WebDriverWait(driver, 10).until(EC.presence_of_element_located((By.ID,'nr')))
txts = element.text.replace("\n","").replace(" ","\n")# 这两句是格式化小说文本,输出到txt文档里保存
txts = txts + "\n" if txts[1] == "第" else name + txts + "\n\n"
with open(r"E:\我靠打爆学霸兑换黑科技.txt",'a+',encoding="utf-8") as f:
f.write(txts)
f.close()
endtime = time.time()
print(name,"已完成!",f"耗时{(endtime - starttime)}秒.")
except TimeoutError:
print("Time out!")
if __name__ == "__main__":
starttime = time.time()
getMainUrl("https://www.keleshuba.net/book/386750/")
endtime = time.time()
print(f"已全部完成,耗时 {(endtime - starttime) / 60} 分钟!")
上面的代码很简单,希望对喜欢爬虫的朋友有借鉴作用,谢谢观看,再见!
PS: with open(r"E:\我靠打爆学霸兑换黑科技.txt",'a+',encoding="utf-8") as f:
这句有小说保存路径,请改成自己的。
本站大部分文章、数据、图片均来自互联网,一切版权均归源网站或源作者所有。
如果侵犯了您的权益请来信告知我们删除。邮箱:1451803763@qq.com