

Python经典案例爬取豆瓣Top250电影数据
随着网络数据的日益丰富,如何从海量的信息中快速、准确地提取出有价值的数据,成为了许多开发者和技术爱好者关注的焦点。在这个过程中,网络爬虫技术凭借其强大的数据获取能力,成为了数据分析和挖掘的重要工具。本文将通过一个经典案例——使用Python爬取豆瓣Top250电影数据,来介绍网络爬虫的基本原理和实际操作方法。豆瓣电影作为国内知名的电影评分和评论平台,其Top250榜单汇聚了众多经典影片。通过爬取这些数据,我们可以对电影市场进行更深入的分析。本文将实现豆瓣Top250电影数据的简单爬取。
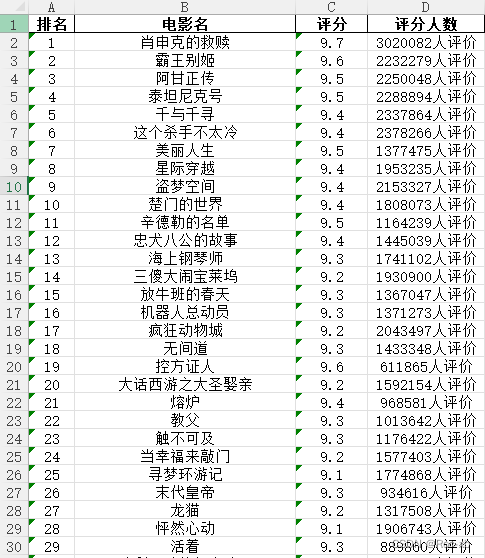
代码如下:
import randomimport time
import requests
from lxml import etree
import pandas as pd
from fake_useragent import UserAgent
# 生成随机的 User-Agent
ua = UserAgent()
# 存储所有电影信息的列表
all_movies = []
# 循环爬取多页数据
for i in range(0, 250, 25): # 每页有25部电影,共250部电影
url = f"https://movie.douban.com/top250?start={i}&filter="
headers = {"User-Agent": ua.random} # 随机选择一个 User-Agent
response = requests.get(url=url, headers=headers)
html = etree.HTML(response.text)
rank = html.xpath('//div[@class="pic"]/em/text()') # 排名
name = html.xpath('//div[@class="hd"]/a/span[1]/text()') # 电影名
score = html.xpath('//*[@id="content"]/div/div[1]/ol/li/div/div[2]/div[2]/div/span[2]/text()') # 评分
people = html.xpath('//div[@class="star"]/span[4]/text()') # 评分人数
tu = list(zip(rank, name, score, people))
all_movies.extend(tu)
time.sleep(random.uniform(1, 2)) # 1-2秒再进行一次循环
df = pd.DataFrame(all_movies, columns=['排名', '电影名', '评分', '评分人数'])
print(df)
# 输出表格
df.to_excel('top250_movies.xlsx', index=False)
版权声明:本文为博主原创文章,遵循 CC 4.0 BY-SA 版权协议,转载请附上原文出处链接和本声明。
原文链接:https://blog.csdn.net/qq_19309473/article/details/138731339
本站大部分文章、数据、图片均来自互联网,一切版权均归源网站或源作者所有。
如果侵犯了您的权益请来信告知我们删除。邮箱:1451803763@qq.com