
Python 爬取免费小说思路

在这篇文章中,我们将一起探讨Python爬虫异常处理实践,特别关注处理被封禁和网站升级问题。让我们一起来看看如何解决这些问题,提高我们爬虫程序的稳定性和可靠性。
HTMLParser是Python内置的专门用来解析HTML的模块。利用HTMLParser,我们可以分析出一段HTML里面的标签、数据等,是一种处理HTML的简便途径。

近年来,随着互联网的快速发展和人们对电影需求的增加,电影市场也变得日趋繁荣。作为观众或者投资者,我们时常需要了解最新的电影排行榜和票房情况。

pymssql包是Python语言用于连接SQL Server数据库的驱动程序(或者称作DB API),它是最终和数据库进行交互的工具。SQLAlchemy包就是利用pymssql包实现和SQL Server数据库交互的功能的。

想知道如何使用Python轻松高效地获取网络上的信息? 本篇文章将探索Python自动化爬虫,并展示如何编写实用的脚本。

随着科技发展带来的信息爆炸期,获得信息变得愈来愈重要。网络爬虫是一种从互联网网站抓取信息的自动化程序,可以搜集大量有价值的数据,并将它们写入到MSSQL数据库中,以便后期分析和利用。

以下是一个简单的Python爬虫完整代码模板,用于演示如何使用requests库和BeautifulSoup库爬取网页内容

pip install sklearn安装成功后,提示ModuleNotFoundError: No module named ‘sklearn‘错误解决办法
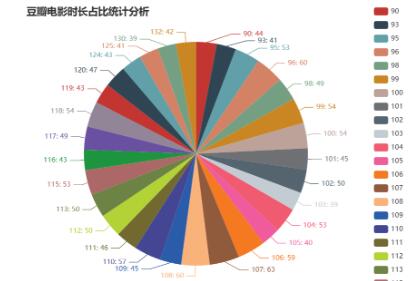
本文基于Python的网络爬虫手段对豆瓣电影网站进行数据的抓取,通过合理的分析豆瓣网站的网页结构,并设计出规则来获取电影数据的JSON数据包,采用正态分布的延时措施对数据进行大量的获取。

